If you are like me, what is the purpose of spinning up a stretched cluster in the home lab without being able to intentionally break things (queue the Tim Allen grunt). I really like doing this as it helps to understand how the vSphere cluster handles failures in the real world. If you saw my post on configuring the stretched vSAN cluster, we looked at how to configure the stetched cluster and configure the dual site mirroring for the site level redundancy. If you have a failure in the primary cluster, your data is still safely mirrored to the secondary location. However, let’s test that theory. We will take a look at vSAN simulated failure of stretched cluster to see how it reacts for VM workloads running in a preferred cluster.
vSAN Stretched Cluster Requirements
The vSAN stretched cluster offers some really amazing benefits and protection and availability for your data. However, it does come at a cost on the requirements side.
The stretched cluster has to fit within certain tolerances to be a viable solution for your environment. Notably, the network latency and network bandwidth requirements are fairly steep:
- Latency or RTT between sites hosting virtual machine objects should be no greater than 5msec which is (<2.5msec one-way).
- VMware also recommends bandwidth between sites hosting virtual machine objects at a minimum is 10Gbps or greater.
These requirements may be hard to swallow for many organizations who simply are limited by the pipe between sites for doing vSAN stretched clustering.
VMware vSAN Stretched Cluster Failover with Dual Site Mirroring
You can take a look at my specific vSAN stretched cluster configuration in the referenced post on how to configure the solution. However, in brief, I am running (6) nested ESXi hosts in a stretched cluster configuration.
As shown in the previous post, the vSAN stretched cluster is configured with the default vSAN storage policy set to use dual site mirroring. This means that you have a mirrored copy of your data in both the preferred cluster and the secondary cluster in the stretched cluster configuration.
In my lab, the witness host is housed on the same host for lab purposes and added to the nested vSphere environment as the witness host. To test the failover process, I can simply power off the VMs that are running the nested ESXi hosts to simulate failures on various fronts which makes testing very easy.
In case you are wondering, I am using William Lam’s Nested ESXi vSphere 7 deployment script to quickly created nested environments. Below, as you see I have a test Linux VM that is housed on the stretched cluster.
The highlighted hosts are the “secondary” cluster hosts. The LInux VM is running on the preferred cluster hosts at the moment.
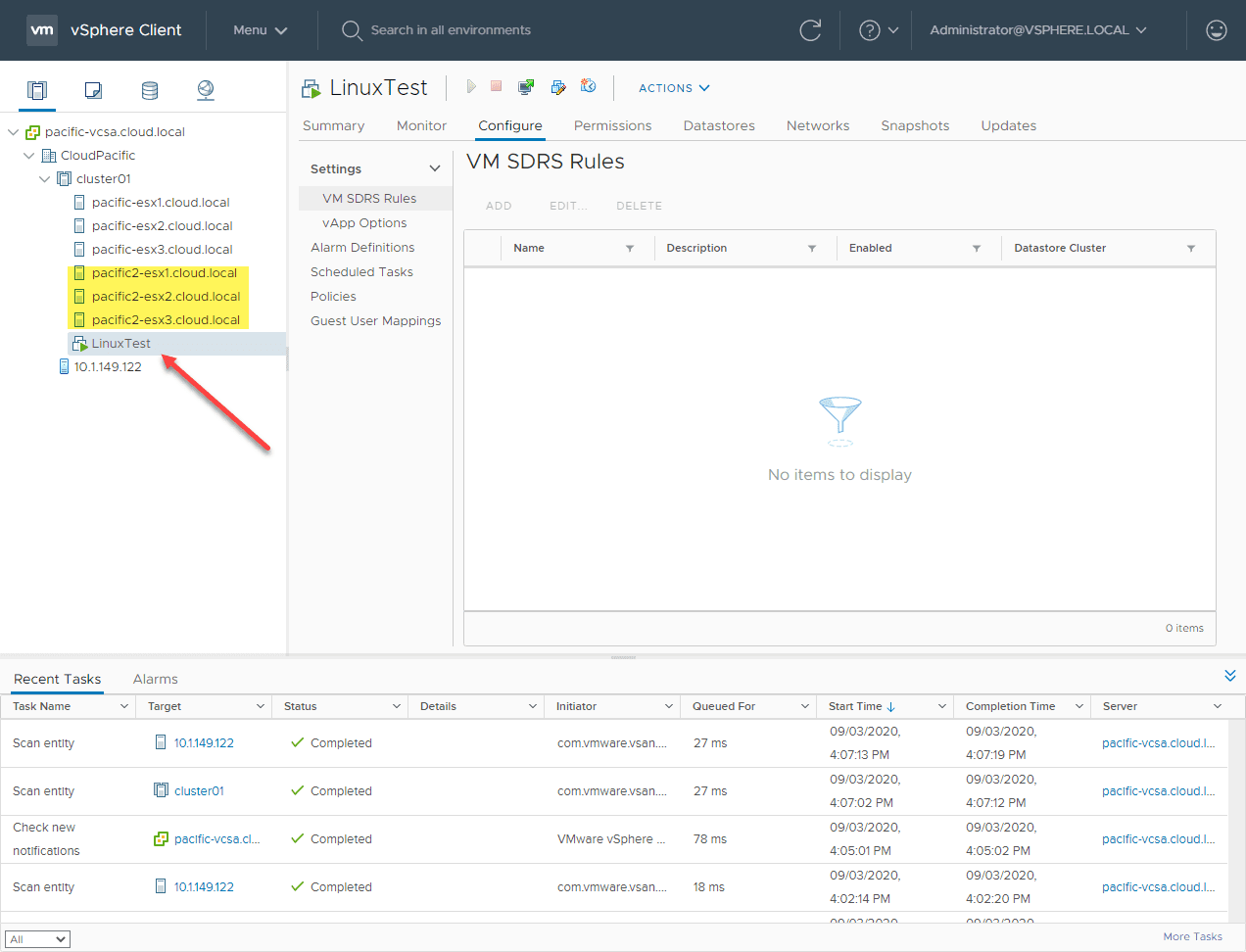
Now, for the simulated failure of an entire site. I am powering off the preferred site ESXi hosts (all of them). This is simulating the failure of an entire site.
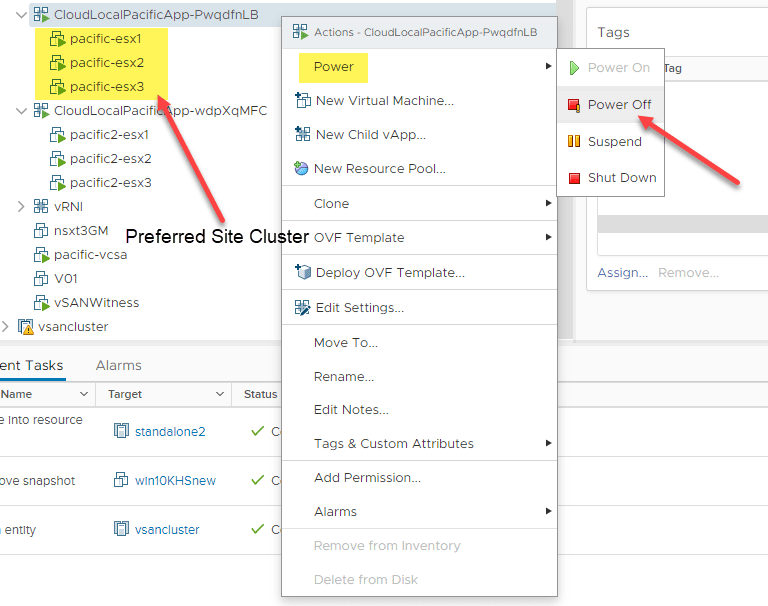
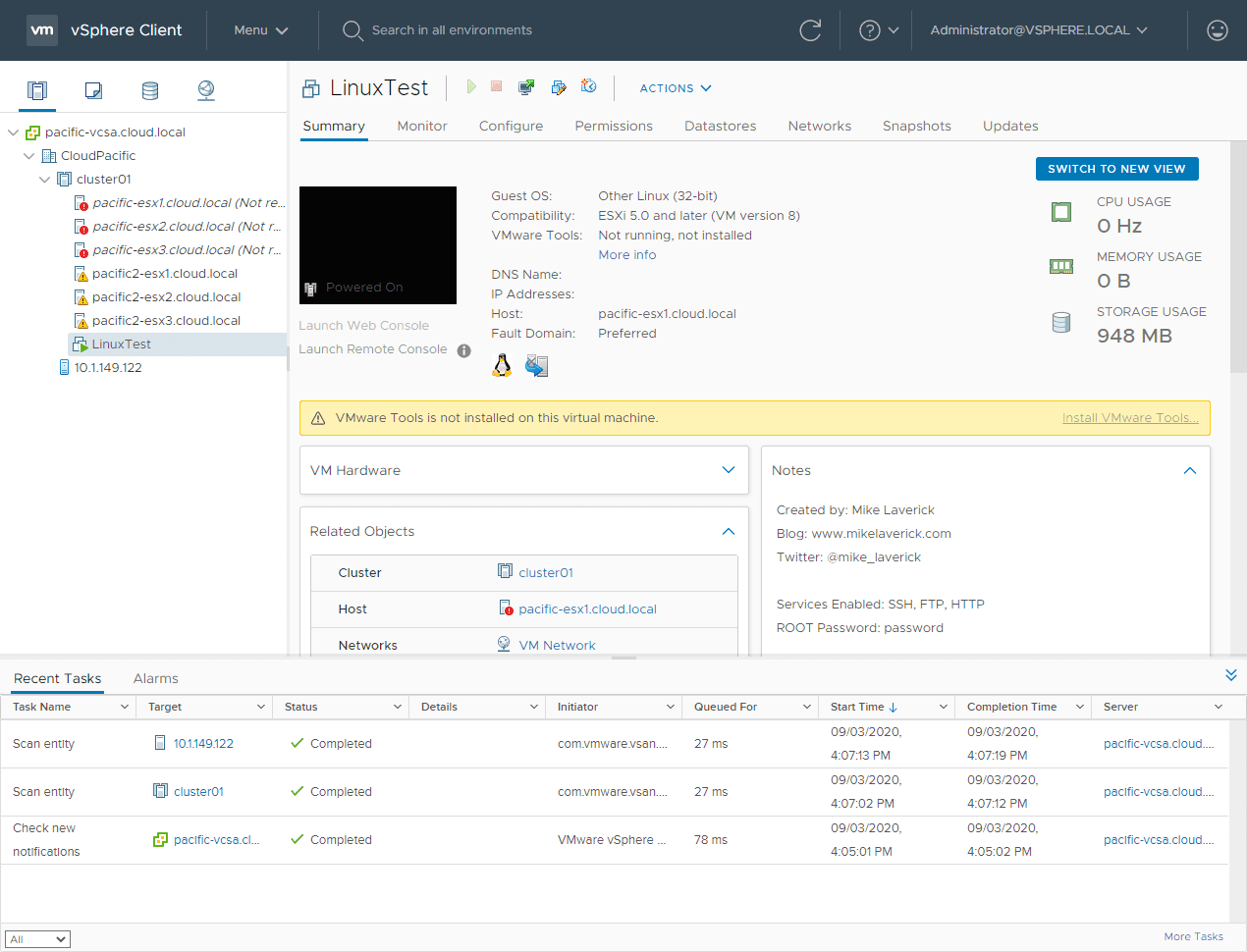
After only a few moments, the preferred cluster hosts show to be not responding.
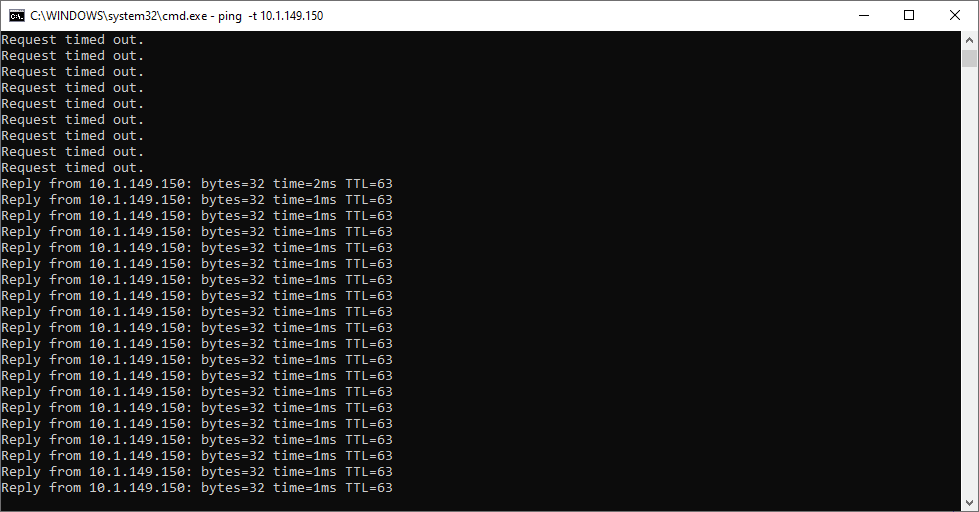
A few moments more and the Linux Test VM is showing as disconnected. The HA process is taking over at this point and will restart the VM on the secondary cluster hosts.
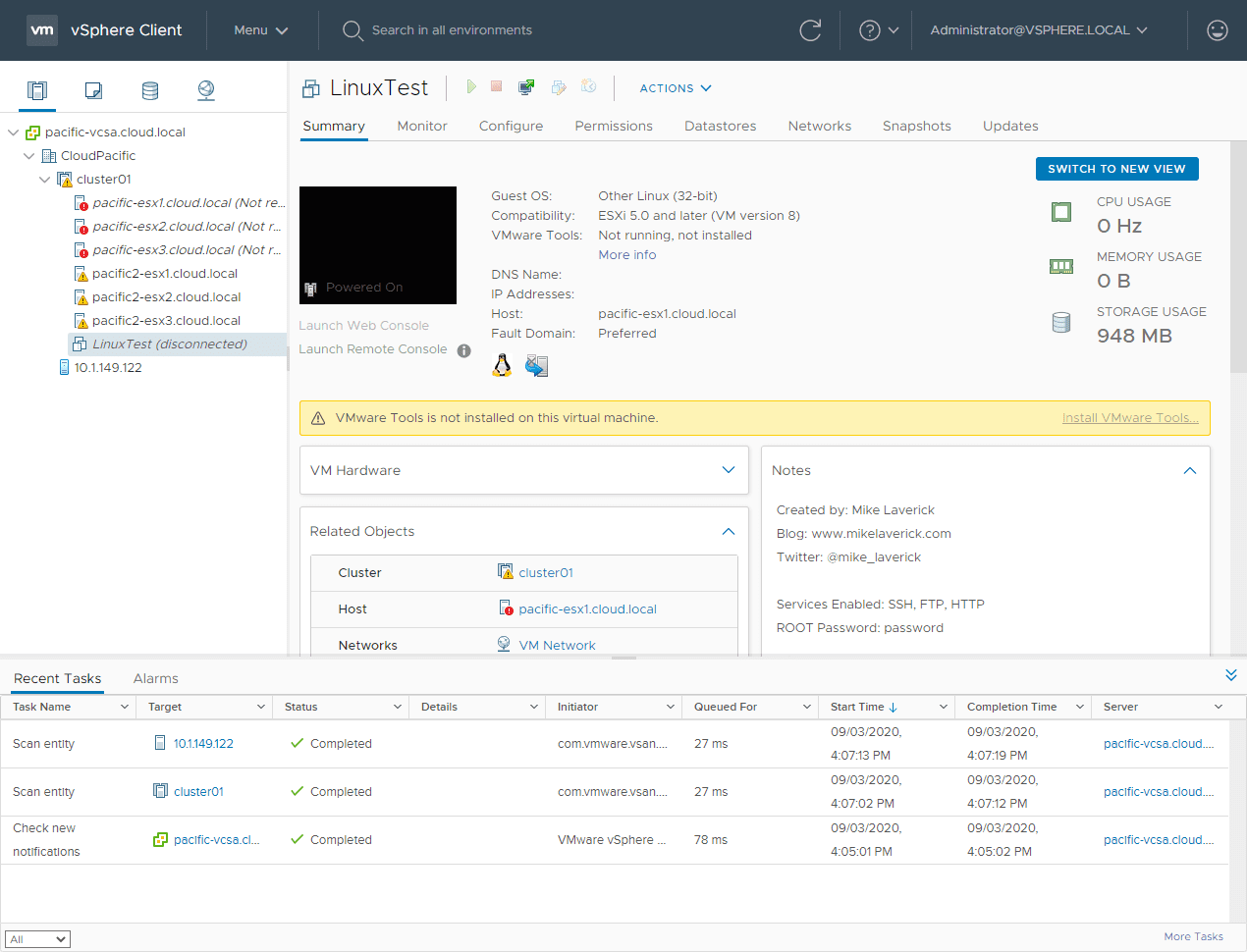
At this point, as you can see, the Linux VM is no longer showing as disconnected and it has powered back on!
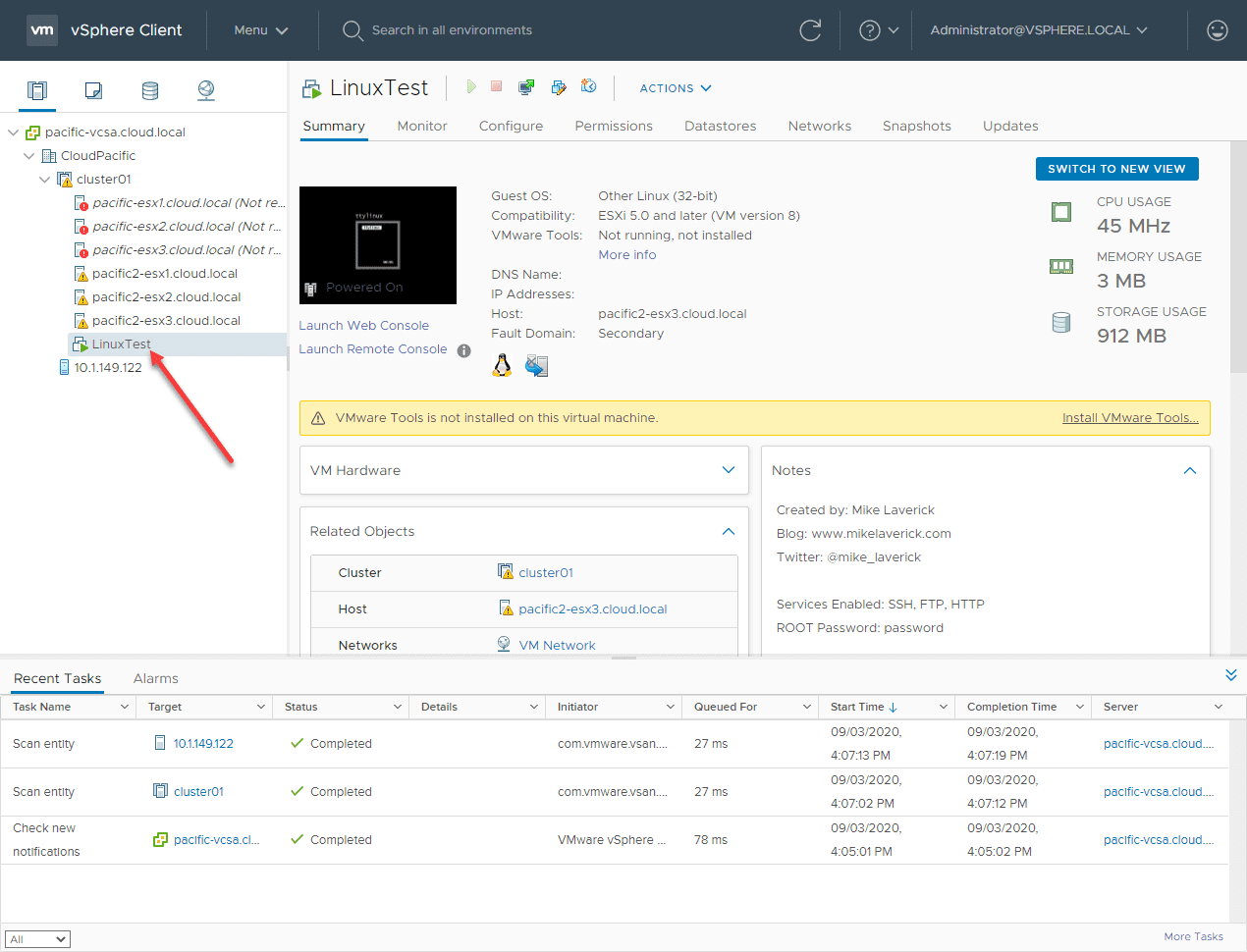
This can be verified by the pings now returning from the VM where they were timing out right after the failure.
What about vCenter Server?
You may be wondering, what if I have vCenter Server housed in the preferred cluster in the vSAN stretched cluster configuration? The great thing about vSphere HA is that it does not rely on vCenter Server to be available.
Once the failure happens in the preferred cluster, the HA process kicks off, even if vCenter Server is down and out for the moment. VMware vCenter Server simply becomes a VM that is powered back on in the secondary cluster.
Restoring the vSAN Stretched Cluster Preferred Cluster
To simulate restoring the production, preferred cluster, I am powering the nested ESXi hosts that comprise the cluster back up.
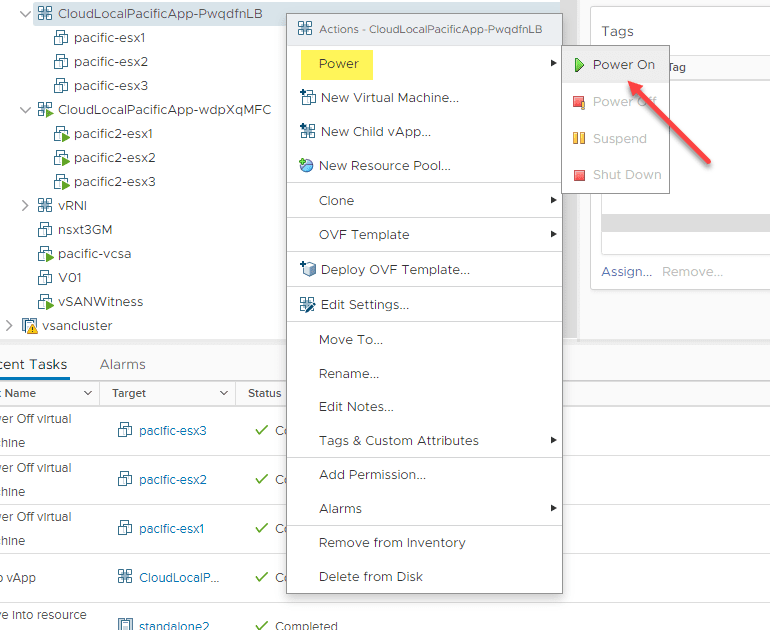
Moving VMs back to the vSAN Stretched Cluster Preferred Cluster
You may wonder, in a disaster recovery scenario, you always want to have a plan to “get back” to where you were before. The great thing about a vSAN Stretched cluster is that it makes this process extremely easy for you.
Using the built-in vSphere affinity rules, you can control which clusters certain VMs are housed on. The way you set this up is with the VM/Host Groups and VM/Host Rules. You have to create your VM/Host Groups first and then use these in your VM/Host Rules.
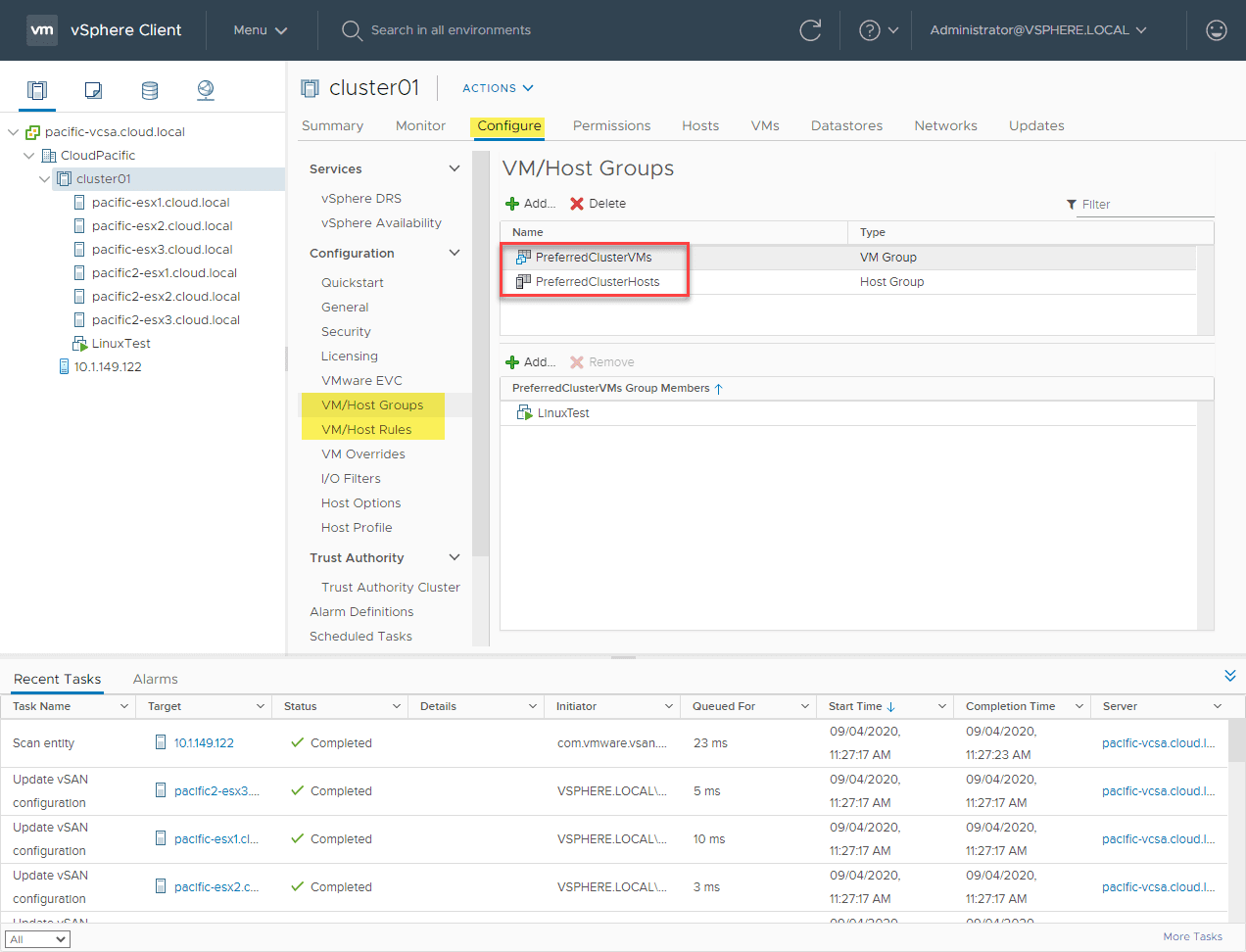
As you can see below, I have a VM Group called PreferredClusterVMs. I have it set to Should run on hosts in group. Then for the Host Group, it is set to a new host group I created called PreferredClusterHosts which contain hosts 1-3 in my lab environment.
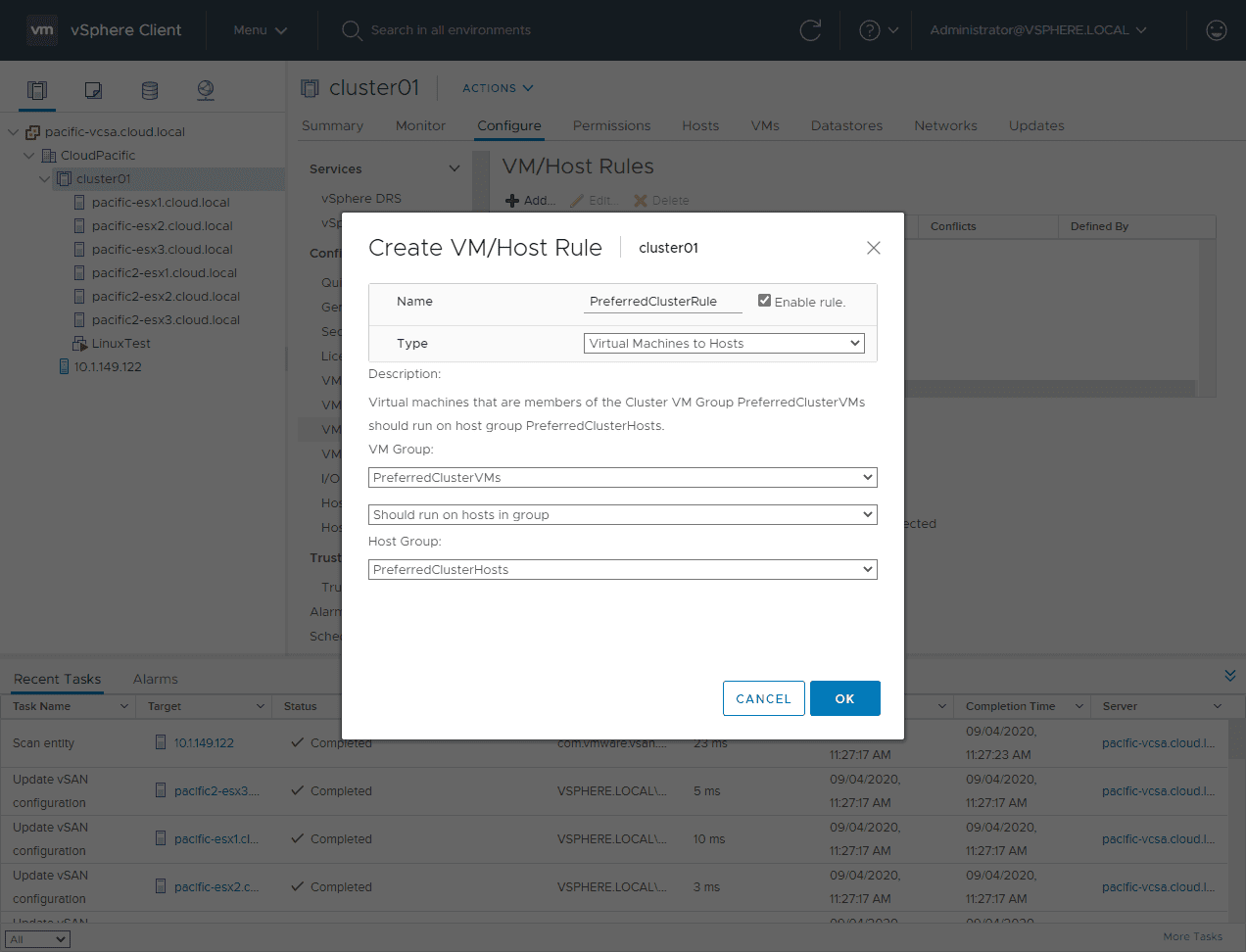
Shortly after creating and enabling the rule, the VM migrates to an ESXi host in the Preferred cluster.

Wrapping Up
The VMware vSAN Stretched Cluster Failover process is amazing to watch as it works it magic. This type of technology helps to totally change the game when it comes to disaster recovery and high-availability for protecting workloads at the site-level.
With the vSAN stretched cluster, you essentially have an RPO of 0 since there is no skew between the data at the production location vs the data in the secondary or DR location. RTO times can be minutes (only long enough for HA to spin up the VMs at the secondary location.
- Read more about the VMware vSAN Stretched Cluster here
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author