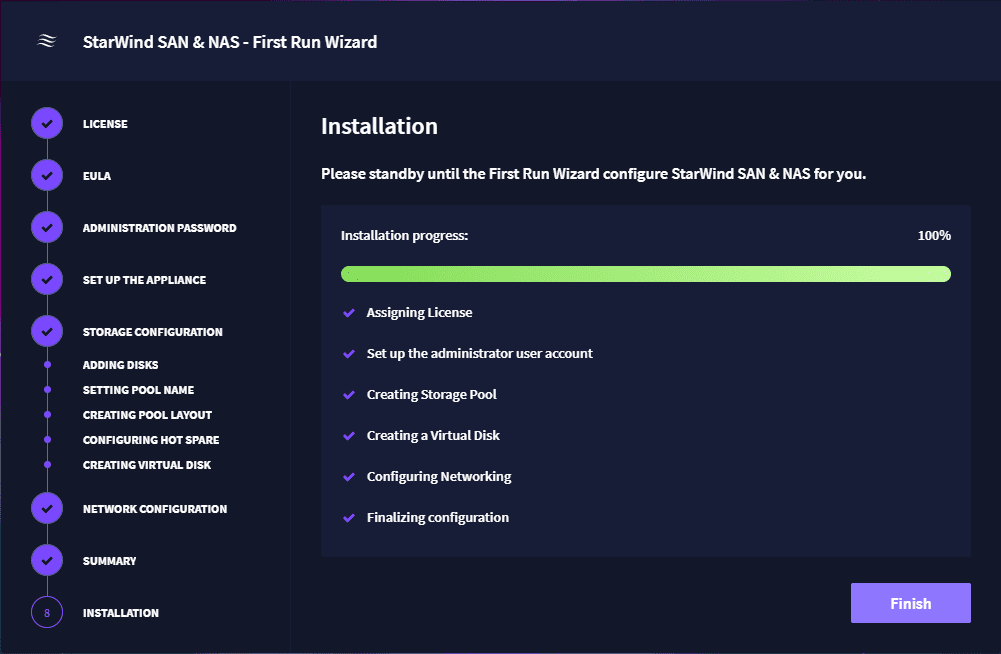
Any type of production infrastructure is generally designed in such a way so as to guarantee high-availability and resiliency. With most types of production systems, you never want to have all your “eggs in one basket” so to speak. You want to have redundancy in all layers of the environment that host your production workloads.
This includes the physical servers, network paths, and storage system. The general requirement of having high-availability and resiliency built into a production systems is usually satisfied with a cluster. In this post, we will take a look at what a cluster is, cluster configuration mistakes, and how these can be avoided.
What is a cluster?
When thinking about high-availability and resiliency, what is a cluster configuration? In simple terms a cluster is made up of multiple nodes that operate in such a way that resources are pooled together and function together as a single system.
There are many different types of clusters. Historically in the SMB and enterprise environment, the Windows Server Failover Cluster is a grouping of Windows Servers that host workloads in an Active/Passive configuration. If a member of the WSFC fails, another node in the cluster assumes running the workloads of the failed host.
Windows Server Failover Clusters have long been used to run resources and applications such as Microsoft SQL Server. This provides a highly available and resilient platform for which a database can remain online irregardless of a hardware failure underneath.
Below is a high-level look at a simple two-node cluster high-level architecture.
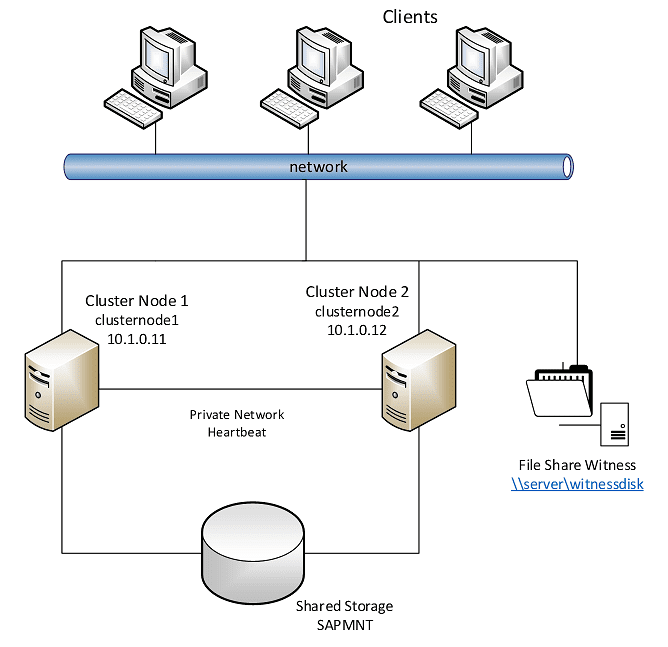
The age of virtualization has brought about clusters that provide resources for today’s virtualized workloads like virtual machines, virtual apps, and others.
In the Microsoft Windows Server Failover Cluster world, Hyper-V is hosted as a highly-available server role that allows providing high-availability and resiliency to your Hyper-V virtual machines. If a single node in the WSFC fails, a heathy node will assume ownership of the VM and restart the VM to bring the resource back online.
In the VMware world, this is a similar concept as multiple nodes makeup a vSphere cluster and provide the high-availability you want to have for your production VM workloads.
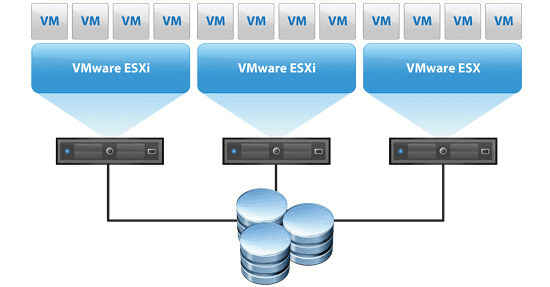
In the VMware vSphere world, at the cluster level, VMware has a component called VMware High-Availability (HA) that kicks in when a node fails. If a failure is detected by the vSphere cluster HA heartbeat, the workloads hosted on the failed node are restarted on a healthy host.
Clusters are generally made possible by some sort of shared storage solution that provides the ability for the data to be accessible simultaneously from any host in the cluster.
If there is a failure, the data doesn’t have to move or be copied anywhere. The remaining healthy hosts simply assume ownership of the files.
Guest Clustering – Another layer of resiliency
In the case of virtualization, having your VMs protected by redundant physical hypervisor hosts is a basic requirement for production. However, with the high-availability mechanisms we have discussed so far, there will still be an outage, even if brief, to the virtual machines.
If the parent host of a VM fails, that VM will be taken down with the host. Then a healthy host will restart the VM and assume ownership. If you want to eliminate the outage for the application hosted by the virtual machine, you can setup guest clustering between a pair of virtual machines.
You are essentially setting up a virtual instance of a Windows Server Failover Cluster nested on top of the physical virtualized environment. Using affinity or anti-affinity rules, you make sure the guest cluster VMs are housed on different physical hosts.
If a physical host fails, taking down the primary cluster “host” VM, the application will quickly failover to the healthy VM. From an end user perspective, they may not see so much as a blip.
However, if only using the physical virtualization clustering, end users would have to wait for the failed host’s VMs to be restarted back on a healthy host for the the application to come back online.
Cluster Configuration Mistakes to Avoid
Hopefully, we now have a bit better understanding of what clusters are, how they work, and an additional layer of protection via the guest cluster. One thing to note, a cluster is only as good as its configuration.
What are some cluster configuration mistakes to avoid? There are several we want to highlight that can lead to your cluster not providing the resiliency you are hoping for and ultimately leading to services disrupted or even data loss.
- Inconsistent host configuration
- Undersizing your cluster
- Having a single point of failure
- Misconfigured network settings
- Misconfigured storage settings
Let’s take a closer look at each of these configuration mistakes and why they are important to avoid.
Inconsistent Host Configuration
Clusters are designed to function as a single, harmonious entity. This is made possible by having consistent configurations across the cluster hosts that make up the cluster.
If you have heterogeneous cluster hosts, this can ultimately result in issues i the environment. For most technologies, having cluster hosts that have the same type and family of processor is an important requirement.
Also, making sure the hosts have the same amount of memory installed helps to ensure there are no issues in the environment with resource allocation between two different cluster hosts.
Make sure other hardware such as NIC cards and other interface cards are configured the same between the hosts. If one host fails, you don’t want to have issues with a remaining host assuming a workload only to find there are hardware differences between the two that can lead to issues.
Make sure other components related to software are configured the same for each host such as the type of cluster operating system, patch level, and any other installed modules in one host vs the other.
Undersizing your cluster
A mistake that can be made on the outset of configuring a cluster is undersizing your cluster. Initially, there may be a certain configuration of hardware based on the projected workloads the cluster will be hosting.
As can happen in many organizations, server sprawl can quickly onset. This is where servers are provisioned beyond the number of workloads the cluster was sized to handle.
This can lead to major performance issues down the road when the server resources are saturated and exhausted by the number of workloads that have been provisioned in the cluster.
Having a single point of failure
The whole purpose of configuring and running a cluster is to avoid having a single point of failure. This means you need to make sure you have redundancy throughout the cluster including:
- Multiple redundant network connections
- Redundant power
- Storage redundancy
The point made about you only being as good as your weakest link is certainly the case with cluster technology. A single point of failure can easily take an otherwise well configured server cluster and its workloads offline.
Misconfigured network settings
The network is the heart of any cluster technology. Clusters generally rely heavily on the network for all cluster related activities. Ensuring the network is configured properly between all participating hosts in the cluster is essential.
A misconfigured network on one or all hosts in a cluster can cause major issues. Additionally, making sure network devices uplinking cluster hosts are configured correctly is essential as well.
Misconfigured storage settings
Making sure storage settings are configured correctly is also essential when provisioning clusters for production workloads. If configuring shared storage for your cluster, you need to ensure the shared storage is configured for simultaneous connections so all hosts can connect to the storage at the same time.
This is important since all hosts need to be able to access storage so failovers can happen as you would expect if a host fails. If a healthy host cannot access the “shared storage” of a failed host, the workload will not be highly available.
Cluster Configure Mistakes Webinar
If you are in the market to learn more about cluster configuration mistakes, StarWind is presenting an informative webinar on this subject. The webinar is entitled:
- Storage Admin’s Nightmare: How to Fail at Building Production Clusters
- July 9th, 11am PT / 2pm ET
- Duration: 60 minutes
It will be chocked full of information on how to avoid making common cluster mistakes, some of which we have mentioned here.

Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author