One of the really nice enhancements of the newest version of vSAN, found in vSphere 7.0 Update 3, has to do with vSAN stretched clusters. VMware vSAN stretched clusters are a configuration that I have blogged about in previous posts. VMware vSAN stretched clusters provide robust capabilities from a high availability and data resiliency standpoint. In this post, we will key in on the vSAN stretched cluster enhancements in vSAN 7.0 Update 3 and see what these enhancements bring to the table.
Read my previous stretched cluster posts here:
- VMware vSAN Stretched Cluster Failover
- Configure VMware vSAN 7 Stretched Cluster
- The Stretched Cluster Feature is Not Supported On This Cluster
- Move VMware vSAN 6.7 Stretched Cluster to Different vCenter Server
Overview of the vSAN stretched cluster
First, let’s look at a quick overview of the vSAN stretched cluster and see what they are and how they work. With the stretched cluster, you have nodes that are part of the same vSphere cluster located in different sites. Since your cluster hosts are located in a different site, they allow you to provide full site-level resiliency in the event you have a site failure.
From an RPO and RTO standpoint, the vSAN stretched cluster provides the type of resiliency that we have all dreamed about for years. Your data exists in a RAID 1 mirror between sites. You can also have RAID1 or RAID5 resiliency intrasite. What this means is if you lose an entire site, you still have all your data. There is no need to failover your workloads using your data protection solution, accepting the data loss between your RPOs, and then trying to figure out how to failback.
In the vSAN stretched cluster, this is all taken care of automatically without data loss. With a simple HA operation, VMs running in a particular site would be restarted in the secondary site.
vSAN Stretched Cluster enhancements in vSAN 7.0 Update 3
New with vSAN 7.0 Update 3, there are some exciting new enhancements that provide more resilience to the stretched cluster. Prior to the vSAN 7.0 Update 3 release, if you lost a site AND the witness host, you would not have a majority of the components needed to run the virtual machines.
VMware vSAN 7.0 Update 3 improves the availability by allowing for all site-level protected VMs and data to remain available when one data site and the witness host appliance are both offline. As mentioned by VMware, this behavior mimics similar behavior found in storage array-based synchronous replication configurations.
New vSAN 7.0 Update 3 Two-node enhancements
This new functionality also applies to vSAN 2-node configurations as well. If you recall, the 2-node vSAN cluster is in reality a specialized vSAN stretched cluster configuration. These are extremely popular for remote and edge use cases. The vSAN 2-node cluster provides a high degree of resilience in the event of a single host failure.
Now, with vSAN clusters with 2-node topologies that have 3 or more disk groups in a host, these can suffer an entire host failure, a subsequent failure of a witness, and a failure of a disk group. If you are counting, that is three major failures in a two-node cluster. Despite these failures, with vSAN 7.0 Update 3, the remaining host can provide full data availability.
Read my two-node stretched cluster posts:
- Two-Node vSAN Performance Tip Disable Site Read Locality
- Replacing VMware vSAN Two-Node Witness Host Checklist
Testing out the new stretched cluster resiliency
So, what I have set up to test the new functionality is a nested stretched cluster configuration with 6 ESXi hosts and a witness node. Three of the hosts are in the preferred site and three are in the secondary site. To setup the lab I have all 6 hosts running on the same physical lab host inside (2) vAPPs to make it easy to “pull the plug” on either site. The witness host is running as the standalone nested ESXi VM on the same host.
Lab hosts:
- (6) workload hosts fully patched to – VMware ESXi, 7.0.3, 18825058
- (1) witness node fully patched to – VMware ESXi, 7.0.3, 18825058
Simulating the first failure
To start, I simulated losing the secondary site. So this is the same kind of failure that vSAN stretched cluster could have withstood in the past. All is good as expected:
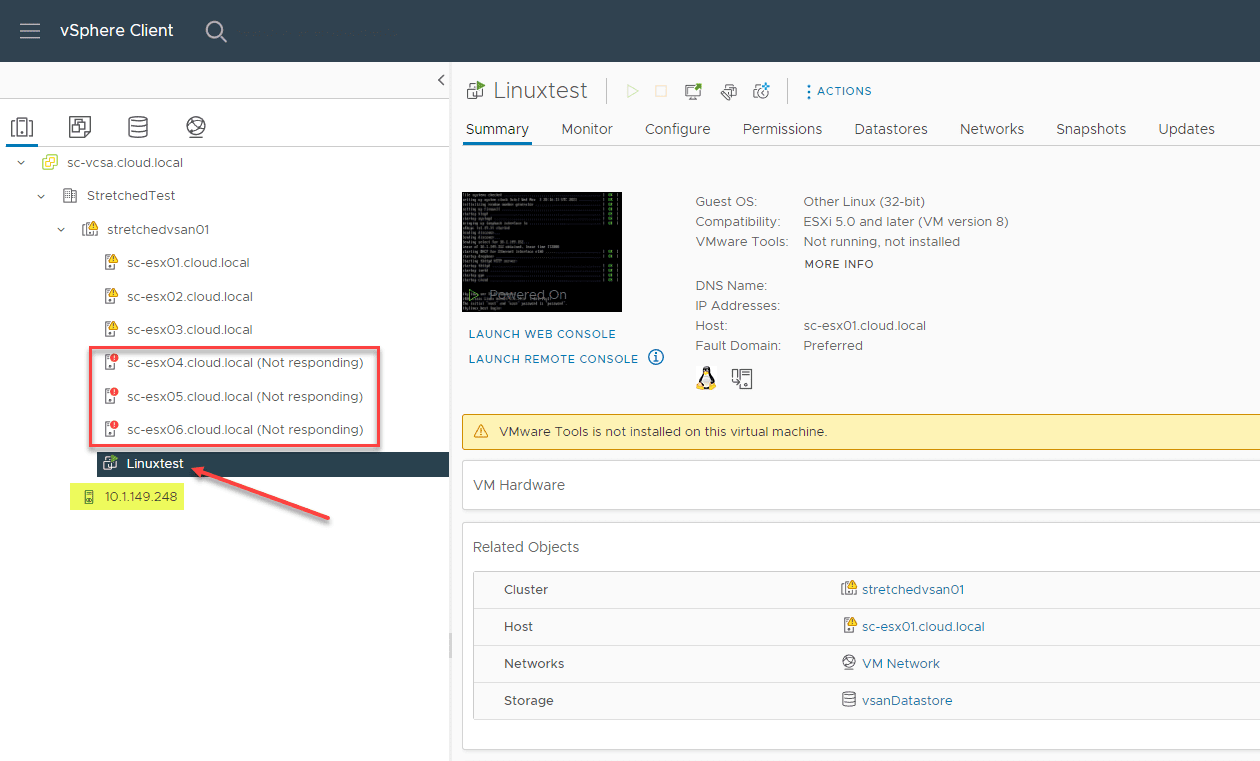
Simulating the second failure
Now, for the real test. I now power the witness host off. So, if you are counting, I have three hosts down in the secondary site, and now the witness host is down also. I waited a couple of minutes just to see what happened and make sure it didn’t go down in a delayed fashion. However as you can see below, the VM is still running, even the following resources are down:
- sc-esx04.cloud.local, sc-esx05.cloud.local, and sc-esx06.cloud.local (workload hosts)
- 10.1.149.248 – witness host
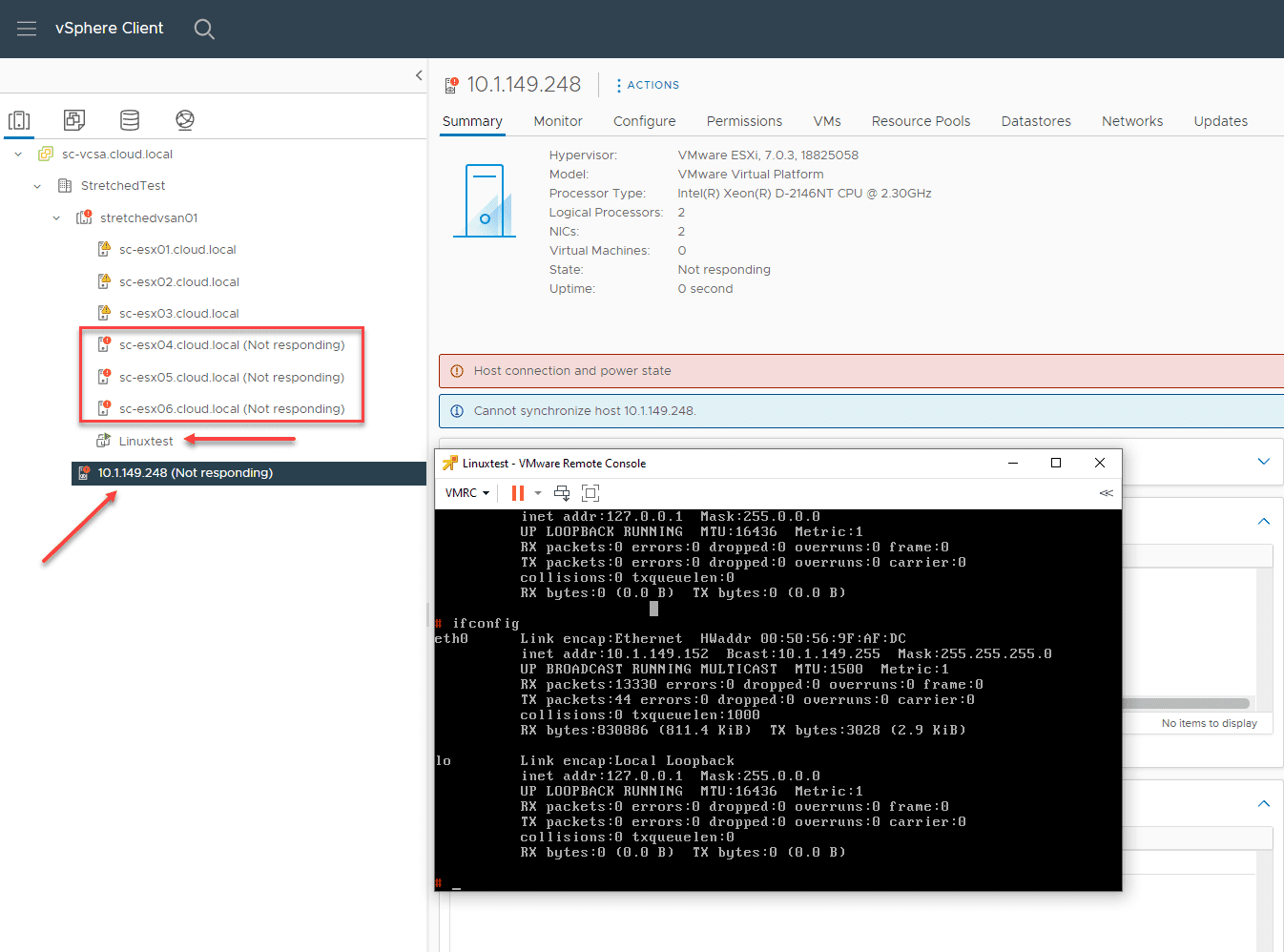
I have to tell you, it was really amazing to see the VM still just purring along like a kitten, even after taking down so many of the resources in the stretched cluster. The new stretched cluster enhancements are indeed remarkable. It is great to see how VMware has concentrated many efforts to improve the resiliency for stretched clusters as this is certainly an architecture I have seen much interest in when designing refreshes, etc.
See two failures in action!
If you would like to see the behavior first hand, take a look at the video I posted here showing a site-level failure and witness node failure with the workload still running.
Wrapping Up
The new vSAN Stretched Cluster enhancements in vSAN 7.0 Update 3 are amazing. This will certainly be a game changer in how customers can design out their infrastructure. It also helps to take the pressure off worries over the witness node going down during an outage of a site.
I have heard rumblings that VMware is also looking at additional options for housing the witness host as well so it will be interesting to see how this develops in the future. For now, vSAN 7.0 Update 3 stretched clusters are the best stretched cluster technology you can use in my honest opinion. If you want the least amount of downtime in the event of a disaster at the site-level, this is it.
More in this topic
Discuss this in the Community
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author
