Troubleshooting Slow VMware Virtual Machine Power On Time
There comes times when you have a single ESXi host that you wish you didn’t! There are certain times when something that is simply for development or staging that supposedly isn’t production, but management may view it as production and your aren’t granted the funds to setup the environment properly for high availability. While this is a discussion for another day – business expectations vs granted budget for virtualization projects, it is what it is. This point aside, I ran into an issue with one of these types of environments where an ESXi host that was heavily loaded went down with a purple screen. After troubleshooting the underlying cause, I needed to power the virtual machines back up. The virtual machines were extremely slow to power on. Let’s look at the topic of troubleshooting slow VMware virtual machine power on time and the typical culprit that I have seen in most environments.
Troubleshooting Slow VMware Virtual Machine Power On Time
In the many times that I have seen this to be the case when Virtual machines are slow at powering on, there are of course hardware and other issues to rule out. However, typically this comes down to slow disk performance or saturated disk subsystem that translates into extremely slow VMware virtual machine power on time. In my case, this last event happenend on an ESXi 6.0 era host housing compute/memory/disk for a lab environment.
The server in question was running an LSI based RAID adapter so I had access to the storcli utilities which are helpful. Using the LSI storcli utilities, you can see current operations running on the storage system.
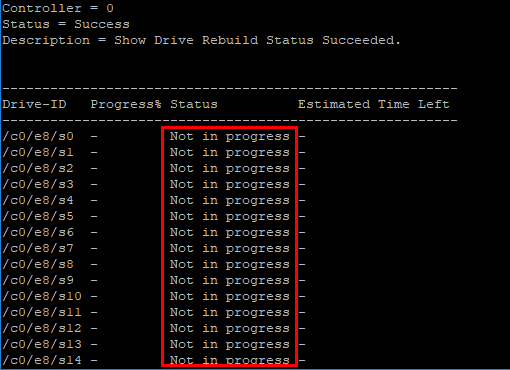
As the server booted, I noted the RAID arrays showed to be healthy and online so no drive rebuilds were currently running. I was able to verify that with storcli using the following:
storcli /c0 /eall /sall show rebuild
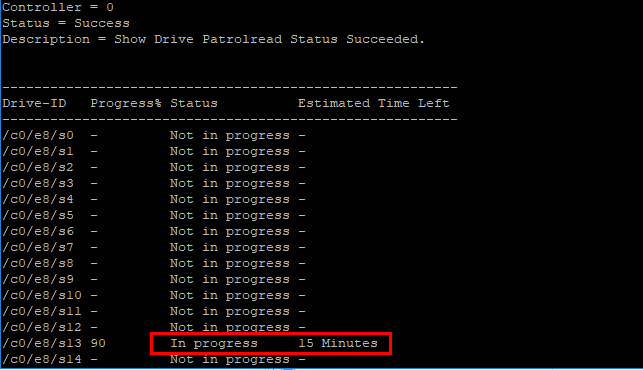
However, was there another operation that was tagging the host disk subsystem? Working on an hunch here, I queried the storcli for any patrol reads that may be happening. What are patrol reads? Patrol read is a feature which proactively attempt to discover disk errors. By default it is done automatically (with a delay of 168 hours between different patrol reads) and will take up to 30% of IO resources on LSI based cards. Let’s see if patrol reads are happening.
storcli /c0 /eall /sall show patrolread
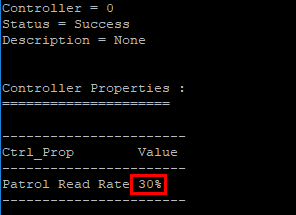
To confirm the written parameters of what percentage of I/O can be dedicated to patrol reads, LSI storcli has a command to do that:
storcli /c0 show prrate
By default the patrol read hit can be 30% which is confirmed by the above command.
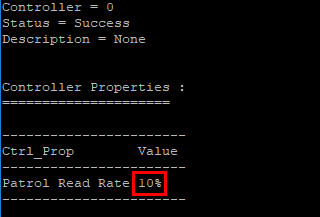
Interestingly you can adjust the patrol read process rate. Storcli has a command specific for that. For instance, if we want to adjust from 30% to 10%, we can do the following.
storcli /c0 set prrate=10
Below, the patrol read has been adjusted to 10%.
With the LSI storcli commands you can also stop or suspend the patrol read process if need be as well which can be extremely helpful if you are trying to get VMs powered back on and the storage subsystem is getting tagged by the patrol read overhead.
Additionally, be sure to check the Events section of your host and most likely during periods of extremely slow virtual machine power ons, I have seen datastore connectivity messages logged.

This can be confirmed through your host.d log file. You can access this log here:
- https://<your host>/host/hostd.log
I saw the similar entries with a bit more detail:
2018-03-13T15:17:49.253Z info hostd[352C2B70] [Originator@6876 sub=Vimsvc.ha-eventmgr] Event 241 : Lost access to volume 58255f5f-84472068-f564-0cc47adea96c (teststore) due to connectivity issues. Recovery attempt is in progress and outcome will be reported shortly.
Thoughts
Troubleshooting Slow VMware Virtual Machine Power On Time can be problematic. However, from my experience in most environments, this is typically related to saturation on the storage side. In the case as demonstrated above, you can use storage utilities to get a better look at underlying processes that may be happening on the storage side that are sapping performance, even if the host has NO Virtual machines running at the moment. You may already be down 30% total I/O in the case of LSI cards, and then adding the I/O produced by the “boot storm” that happens on a single host trying to power on a large number of VMs and the boot I/O that happens by extension.