Disaster recovery is one of the most important aspects of IT operational planning and in thinking about business continuity. Organizations today are very data driven with the need for always available data driven infrastructure as is often found in today’s web facing e-commerce driven businesses. When it comes to major disasters that stem from widespread damage such as occurs in a natural disaster or other disaster that affects a large geographic region, organizations must plan for and architect infrastructure to account for entire site recovery. In this post, we will look at the Top 5 Considerations for Site Recovery in disaster recovery scenarios and how organizations can plan for and account for these considerations in an automated way.
Top 5 Considerations for Site Recovery
When thinking abot site recovery, organizations need to think proactively and also think about business continuity when it comes to a total site failure. Typical DR involves restoring files, folders, or even entire virtual machines or multiple virtual machines in the same site. When restoring data in the same site, you have way fewer considerations that need to be made than when restoring data and services in a separate, recovery site. Why is this the case? Let’s think about the top 5 considerstions for Site Recovery which highlights these often neglected areas when thinking about site failover. Let’s look at the following:
- Replication
- RPO and RTO
- Network Reconfiguration
- Automating Failover and Failback
- Testing Site Recovery
Each of the above are crucially important when thinking about Site Recovery and the overall plan for business continuity. Let’s look at each one in greater detail and see how organizations can use a solution such as NAKIVO Backup & Replication, which is a modern data protection solution, to effectively meet the technical challenges involved with each aspect of the above top 5 considerations.
Replication’s Role in Site Recovery
The first crucial component of a site recovery disaster recovery plan is to replicate virtual machines to a recovery site. Replication is the process of taking an exact image-level backup of a production virtual machine and replicating that data across to a recovery site virtual environment running your hypervisor of choice. Most organizations run homogenous hypervisor environments both at the production location and the recovery site location. A modern hypervisor solution such as NAKIVO Backup & Replication allow organizations to effectively and efficiently replicate production environments to a recovery site. Using a VMware vSphere environment as an example, NAKIVO can make use of changed block tracking to only replicate the changed blocks once the initial replication of the virtual machine is complete. Using the job chaining feature, organizations can chain together backup jobs as well as replication jobs so that as soon as a production backup job runs, the replication job can be initiated as well. Additionally, you can set job schedules that allow effectively scheduling replication of virtual machines at specific or certain intervals.
One of the considerations to be made with replication is that replicated virtual machines generally traverse the WAN connection since, most often, the recovery site is located outside the production site. Generally, recovery sites will be connected either via the Internet via site-to-site VPN or a private MPLS circuit. Initial replication of a virtual machine can represent a tremendous amount of data that would need to traverse the WAN link which may affect production Internet connectivity or other business critical connectivity with cloud or other services. “Seeding” replicated virtual machines allows placing a recent copy of a production virtual machine in the replicated environment and then “mapping” a replica virtual machine to the restored virtual machine in the replicated environment. NAKIVO allows organizations to effectively map replicas to these “seeded” virtual machines, saving time and precious/expensive bandwidth between sites.
It is important to realize that if you only replicate virtual machines in the off-peak hours of production, if a site-wide disaster occurs before the replication interval kicks off, the recovery site may not have the most recent changes between production and the recovery site. Seeding the initial replica to the recovery site will certainly be a major help with the amount of data that is copied across the production WAN or MPLS circuit. Changed block tracking also helps to ensure only the changes made are copied with each respective backup iteration. However, this is a consideration of RTO and RPO when it comes to site recovery. This leads us into the next consideration.
RPO and RTO Importance in Site Recovery
There are arguably no greater terms of importance when it comes to data protection than the Recovery Point Objective and Recovery Time Objective metrics. Starting with Recovery Point Objective or RPO, the RPO is the amount of data you can lose when it comes to backups or replication. In other words, the point that is either backed up or replicated is the snapshot of your data that you have in that location. If you replicate your data every hour as an example, the maximum amount of data that you would lose is an hour’s worth of data since at most it would be an hour before new data is backed up or replicated. The tighter the RPO, you will be copying less data with each run, but would creating snapshots on production virtual machines more often. There is possibly a tradeoff here. However, generally speaking on your production virtual machines, it can be a business decision to see how much data is OK to lose. Typically, you want this to be as low as it can be.
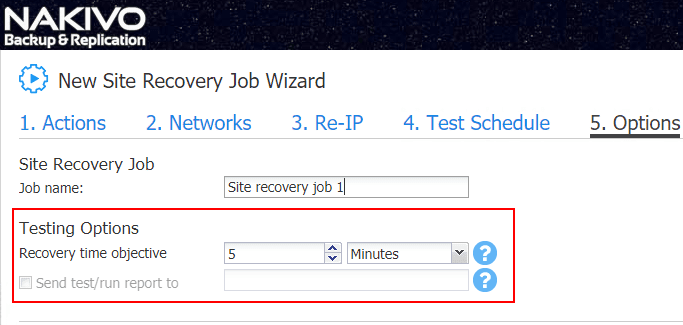
Recovery Time Objective or RTO, is the amount of time it takes to restore the RPO or bring that snapshot of data, virtual machines, services, back online. Typically, you want the RTO to be as low as possible. With NAKIVO Backup & Replication organizations can make use of “instant VM recovery” or “Flash VM Boot” to allow the virtual machine or machines to be booted directly from storage to help with this if in the main production location. However, when thinking about site recovery, the processes and procedures to take care of the very detailed and tedious work of getting replicated virtual machines configured for the DR environment directly impacts the RTO. As we will see NAKIVO has very powerful features and functionality in NAKIVO Backup & Replication v8.0 that allow organizations to automate and orchestrate these activities to be as quick as possible, leading to extremely low RTOs.
Network Reconfiguration During Site Recovery
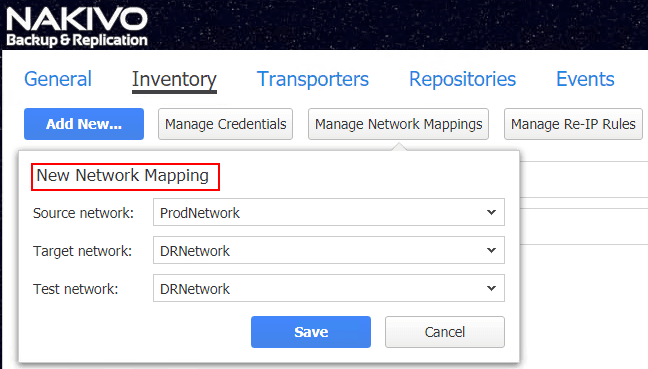
One of the most tedious tasks that affects the RTO during site recovery at a recovery site is the reconfiguration of network settings on replicated virtual machines. Why is this necessary? In thinking about how networks are configured, the production network configuration is most likely going to be different than the target recovery site. This is because in general for IP traffic to be routed correctly, the IP addresses and subnets need to be unique between the production and recovery site. Most likely organizations will be running different internal subnets at the production location and the DR/recovery site location. So, when production virtual machines are replicated to the recovery site, they are an exact copy of the production virtual machines in every way, including the configured network settings. This means if you simply power on the virtual machine in the recovery site, the configured IP addresses, DNS servers, and gateway configuration will all be incorrect for the network configured at the recovery site.
Additionally, the port groups configured on the replicated virtual machine, in the terminology and case of VMware, will be carried over from production. The network labels of the recovery site port groups would also need to be changed for proper traffic flow. Both of these details can create a lot of work for administrators bringing up virtual machines in a recovery site during a disaster recovery scenario. Thinking about a typical scenario where administrators would have to manually intervene, would involve changing IP addresses, subnet masks, DNS servers, and gateway for all the replicated virtual machines that need to be brought up in the recovery site. This may be doable for 10 or so virtual machines, but what about 50 or 100, or even more? This would represent a tremendous amount of manual effort. More importantly, this would drastically affect the RTO during a disaster recovery scenario involving the need to recover an entire site.
NAKIVO Backup & Replication v8.0 provides powerful site recovery functionality that allows administrators to be able to automate the network mapping and IP address configuration of the replicated virtual machines. This means that as the new virtual machines are brought online in the recovery site, NAKIVO Backup & Replication automatically reconfigures the network settings on all the virtual machines to match the recovery site network space as well as the network label matching the correct port group that needs to be connected to properly connect the VM and allow traffic to flow properly. Being able to automate this process not only speeds RTO up drastically, but it also helps to eliminate the chance of human error in the reconfiguring of massive amounts of virtual machines.
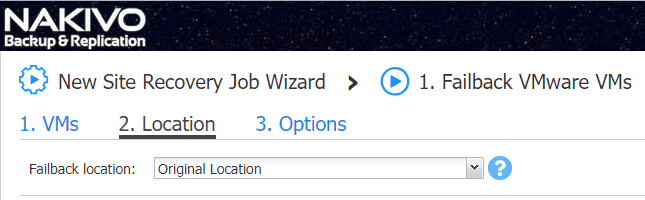
Automated Failover and Failback
Having a centralized way to control and oversee the actions and tasks involved with transitioning from a production site to a recovery site via a failover of virtual machine resources is certainly preferred over manually performing these tasks by hand. NAKIVO Backup & Replication not only provides the Failover Plan that allows you to automate and orchestrate the failover from production to recovery site, it also provides the ability to Fail back to the production site once the issue is resolved that led to a Failover event.
NAKIVO Backup & Replication includes a new Site Recovery Orchestration job that allows taking an automated approach to many of the tedious tasks involved with site failover and failback processes. This can include things such as performing the actual failover or failback, reconfiguring the network settings of the virtual machine, starting the virtual machine, etc.
By providing this automation and orchestration engine for site recovery, solutions such as NAKIVO Backup & Replication take the heavy lifting out of the process of failover and failback. Not only can you group your virtual machines into site recovery plans and have them start in the order you want, but also, as mentioned, you can completely reconfigure network port group mappings in the virtual environment as well as reconfigure IP addressing. Additionally, in the event of a planned site failover, you can have NAKIVO perform the changed block copies that are needed to bring the replicated copy up to date. These changes can also be replicated back during a failback event.
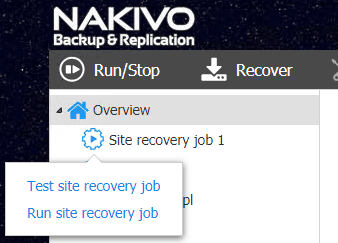
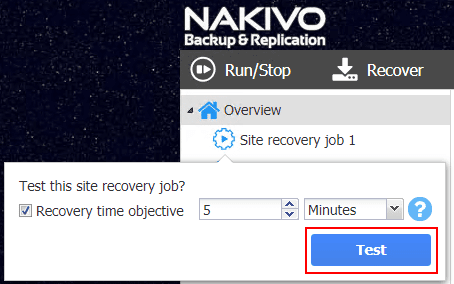
Testing Site Recovery
There is perhaps not a more overlooked area of disaster recovery than testing a disaster recovery plan. Typically organizations assume that backups, replicas, and a business continuity plan is good to go without testing it. This is a dangerous assumption to make. Too many businesses find themselves in an extremely bad situation by having VMs that are corrupted or data that was assumed to be backed up that was not really backed up. By testing disaster recovery, businesses can ensure that all of the data, virtual machines, nuances, tedious tasks are truly successful to bring virtual machines, data, and services back online without issue.
When it comes to both testing your backups as well as site recovery, NAKIVO Backup & Replication provides a means to do both. The screenshot verification mechanism in NAKIVO allows booting VMs and sending administrators a screenshot of the booted virtual machine. The Site Recovery Orchestration job can be used to test Site Recovery processes as well. What is great about the Site Orchestration wizard is that you can set the RTO time you want to use as the metric to test if the recovery job completes acceptably.
Takeaways
There are several key considerations when thinking about diaster recovery and specifically with site recovery. In the Top 5 Considerations for Site Recovery we looked at 5 of the major areas of considerations for businesses looking to effectively architect a site recovery plan. We looked at utilizing tools available in NAKIVO Backup & Replication v8.0 which provides very powerful site recovery mechanisms that allow organizations to orchestrate and automate the processes involved with successful site recovery. With site recovery there are many more “moving parts” that must be considered than with simple recovery of data or virtual machines in the same site. By taking these major points into consideration, especially with testing a site recovery plan, businesses can ensure a validated site recovery plan that is tested and ready to go when a business truly needs it – when a disaster strikes and takes a production site down.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author