If part of your system administration tasks involve managing storage especially for virtualization host targets, there are several things that you should probably be doing on a weekly basis to make sure the environment is healthly. The steps I outline below are centric to VMware and Equallogic environments as that is primarily what I am currently dealing with in the hypervisor/storage realm as of late, but the principles and general tasks should be able to be checked in any hypervisor/storage enviroment. Let’s take a look at the storage admin weekly checklist of areas that need attention when it comes to storage. Note the checklist can be performed at any interval that makes sense in your environment.
Storage Admin Weekly Checklist
Disk Checks
Part of my storage admin weekly checklist tasks are checking disk errors on actual hard disks in arrays. Most proprietary monitoring software that monitors SANs from the vendor have some way to monitor drive errors or failures. Below is a shot from SANHQ for Equallogic:
I like to take it a step further by proactively monitoring the disk errors from the command line. With Equallogic arrays, this is a fairly simple operation to do from the tech support command prompt. If you would like to know more detail of this particular process, check out the post I wrote up. In short though, it involves going in tech support mode and running the following:
diskview -j
This is helpful as it can give you a proactive view of errors, bad blocks, etc on your drives. If I see a drive that is dramatically increasing errors, I can usually predict that it will fail fairly soon and be prepared.
Performance Checks
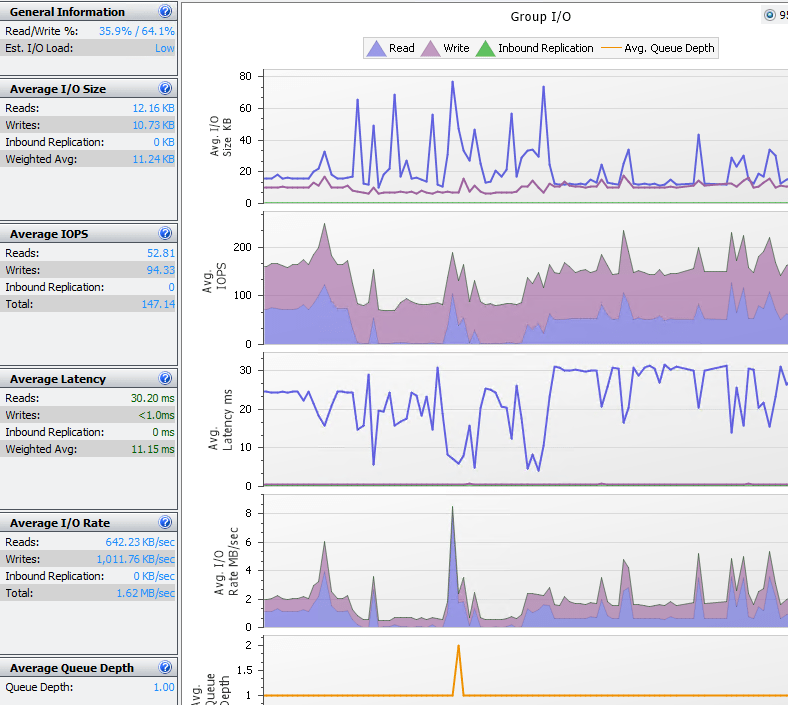
Of course a good indicator of storage health is how well the storage device(s) are performing. Again most probably have a proprietary SAN monitoring solution that can tell you how much latency your array is experiencing along with queue depth, etc. Along with software monitoring of your SAN, there is also builtin monitoring from a VMware vSphere itself. After selecting a host or cluster, simply click the performance tab which will give you the means to look at an overall health of your environment. Below, I have selected datastore and looking at the latency of the datstores on a particular host.
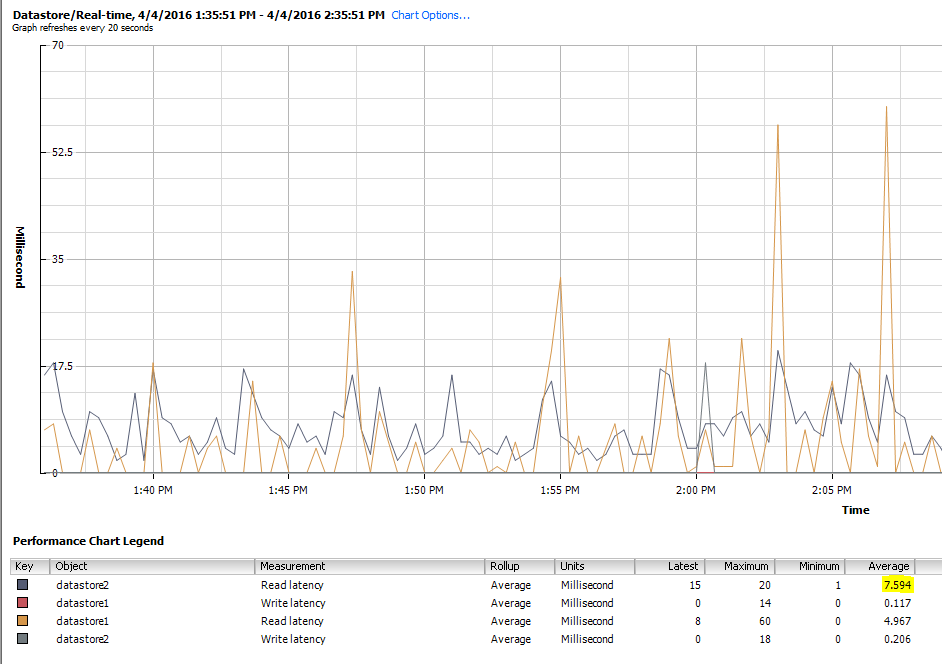
The above shows a fairly healthy box with some peaks. We like latency to be around 5 milliseconds and never sustained above 20 milliseconds. This can give you an idea of your storage performance from within the vSphere client itself.
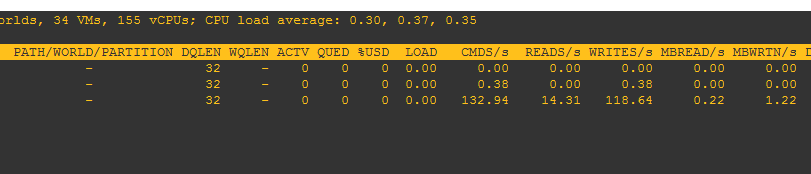
ESXTOP is a great resource for gathering quick information from the command line of your host. You can run esxtop then u and then f to select your metrics:
Disk/Datastore Space
Free space is definitely something a storage administrator needs to keep a check on as running out of space on a LUN is not a good thing and can lead to corruption within datastores. Of course within ESXi we can keep an eye on datastore space, however, this isn’t always indicative of what the SAN thinks free space totals are available. Speaking back to Equallogic, the group manager doesn’t see the think provisioning that VMware is doing and sees the entire amount of proposed blocks as being utilized. If you are think provisioning VMs this can lead to its own challenges. See my write up about zeroing your storage array back out after deleting thin provisioned VMs.
VMware snapshots can grow exponentially over time, so it is a good idea to keep these in check and have a way to monitor your snapshots in your enviroment. Take a look at this solution for querying and reporting snapshots in your environment, which you can then have sent via email as an attached report.
Final Thoughts
Having a checklist on health checks within an environment is a good practice to implement. No matter how much automation you can do, it is a good idea to perform some spot checks either with a weekly checklist of sorts or at an interval that makes sense in your environment. Let me know what metrics and checks you guys are doing in your environments in the comments below.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author