Recently, I ran into an odd issue with a VM that was configured in a three node VMware vSphere 6 cluster. The cluster housed about 30 other VMs that were functioning properly and had no issues. After powering off one VM in particular for some disk maintenance and attempting to power back on, the error popped up in vCenter: the available memory resources in the parent resource pool are insufficient for the operation. In this particular environment, we are using the VCSA 6 appliance.
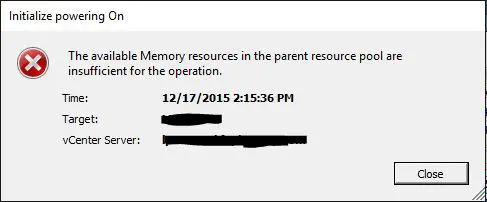
The odd thing was, there were no resource pools that had been setup. Nothing was reserved and resources were wide open for the taking. All other VMs we tested powering off and back on (even those with more memory configured) had no issues powering back on.
After Googling quite a bit and not coming up with anything that fit our environment, I had the thought to bypass vCenter and attempt to power on the VM directly from the host. Bingo! The VM powered on without issue and vCenter was happy as well showing the VM powering up and then powered up.
2015-12-09T17:03:12.122Z info vpxd[7F9A700] [Originator@6876 sub=drmLogger opID=623483199-0000040C-62-25] Drmdump written: /var/log/vmware/vpxd/drmdump/domain-c7/3648389000-mapVm.dump 2015-12-09T17:03:12.122Z warning vpxd[7F9A700] [Originator@6876 sub=drmLogger opID=623483199-0000040C-62-25] [Drm] RemovePoweringOnVms: removing TESTSQL because its mem min 1094741824 exceeds available resources 736527 2015-12-09T17:03:12.165Z error vpxd[7F9A700] [Originator@6876 sub=drmLogger opID=623483199-0000040C-62-25] DrmFault: reason powerOnVm, vm TESTSQL, host NotFoundObject, fault [N3Vim5Fault32InsufficientMemoryResourcesFaultE:0x7f9354f6eb30]
As you see above, vCenter thinks the TESTSQL VM exceeds the available resources. What was also strange is that in addition to no reservations being setup, DRS was not at play either. The VMX files for the affected VM was also not the culprit:
sched.cpu.units = "mhz" sched.cpu.latencySensitivity = "normal" sched.scsi0:0.shares = "normal" sched.scsi0:0.throughputCap = "off" sched.scsi0:1.shares = "normal" sched.scsi0:1.throughputCap = "off" sched.scsi0:2.shares = "normal" sched.scsi0:2.throughputCap = "off" sched.scsi0:3.shares = "normal" sched.scsi0:3.throughputCap = "off" sched.scsi0:4.shares = "normal" sched.scsi0:4.throughputCap = "off" sched.cpu.min = "0" sched.cpu.shares = "normal" sched.mem.min = "0" sched.mem.minSize = "0" sched.mem.shares = "normal"
Resolution
The resolution in our case was reregistering the VM. When reregistering a VM, vCenter generates a new vmid or Inventory ID that won’t be allocated any ghost reservations.
Procedure
- Power down the VM
- Log into vCenter
- Power off the VM
- Remove the affected VM from vCenter in the web client – VMware KB on procedure
- Register the VM on vCenter – kb.vmware.com/kb/1006160
- From vCenter, power on the VM.
After powering down and reregistering the VM, the error went away for the affected VM.
If you have run into a similar bug with vSphere 6 or the VCSA appliance, please pass along your thoughts in the comments below as to any other alternate resolutions you may have come across.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author