If you are wanting to get into running AI models on your local workstation or home lab server, you may assume that you need to have the latest video card or a video card that costs hundreds if not upwards of $1000 to get started. However, this is honestly not the case. You can actually use a fairly old card and much older than what you might imagine. That’s exactly the question I wanted to answer by dusting off my NVIDIA GTX 1060 6GB card. This card was originally released in 2016. The GTX 1060 has been an extremely popular GPU to be used for various things. But could it still be useful for running LLMs (Large Language Models) locally in 2025? Surprisingly yes! You can run quantized language models using platforms like Ollama and OpenWebUI. Let’s take a closer look.
Why try AI with an old GPU?
You might imagine, the answer here is pretty obvious. Old cards can be had for cheap, especially on Ebay. Below are a few reasons you might spring for an old card to start out tinkering with local AI running on your home server:
- They are affordable: You may already own a GTX 1060, or can buy one secondhand for $50–$80
- DIY and learning: For developers and hobbyists, the best way to learn AI is to run it locally and starting with an old card means that you don’t have to have a huge investment
- Privacy: Running models locally avoids sending your prompts to third-party APIs and your data stays local to your network
- Offline access: No internet required
- Home lab and repurposed gear: Repurposing older gear is part of the home lab mantra
Granted, this card will not win any AI benchmarks any time soon, but it will provide a surprisingly capable environment that will allow you to start getting your feet wet with running local language models.
The hardware I used and testing
Here’s the hardware I used for testing with the GTX 1060:
- GPU: NVIDIA GeForce GTX 1060 6GB
- CPU: AMD Ryzen 9 7945HX processor
- Host OS: Ubuntu 24.04 (running as a Proxmox VM with PCI passthrough enabled)
- VM is assigned 8 procs and 20 GB of RAM
- Ollama was installed using the official bash script in the VM
- Containers: LXC container running as a Docker host running
openwebui - CUDA Driver: Version 570
- Tools Used:
- Ollama – for model management and GPU-accelerated inference
- OpenWebUI – front-end UI for Ollama
- nvidia-smi – for monitoring GPU performance and VRAM usage
Getting started was easy. I launched the LXC container and installed Docker along with Docker Compose. The VM was loaded and Proxmox was configured to pass the NVIDIA GTX 1060 through to the VM. The NVIDIA driver was installed. Then the GTX 1060 was detected.
To run a model, you simply use the run command with Ollama. Below is an example:
ollama run mistralAnd within minutes, you can interact with a local chatbot that doesn’t require an Internet connection or API key.
Observations with the GPU and the system CPU
I had some interesting observations about using the old GPU in the context of AI. I had no issues getting it working with Ollama and saw the GPU used with chat queries. However, one thing to note, what I saw was the GPU wasn’t fully used and the CPUs on the virtual machine were still tagged with some of the chat performance.
My hunch is that since it is such an old card, part of the work was being offloaded to the GPU and then with the lack of tensor cores and other features, part of the work was still being done by the vCPUs I had assigned to the system from Proxmox.
The GTX 1060 has:
- 1280 CUDA cores
- 192-bit memory bus
- No Tensor cores
Because the GTX 1060 lacks optimizations specific for AI/ML inference tasks (especially those involving quantized models), these may not be parallelized or offloaded fully to the GPU. So, some of the work spills over to the CPU. This happens especially with token decoding, memory mapping, or data preparation steps. Also, it can depend on the size of the model.
For instance, the below tests are running with gemma3:4b. Running the command below to look at GPU performance:
sudo watch -n 1 nvidia-smi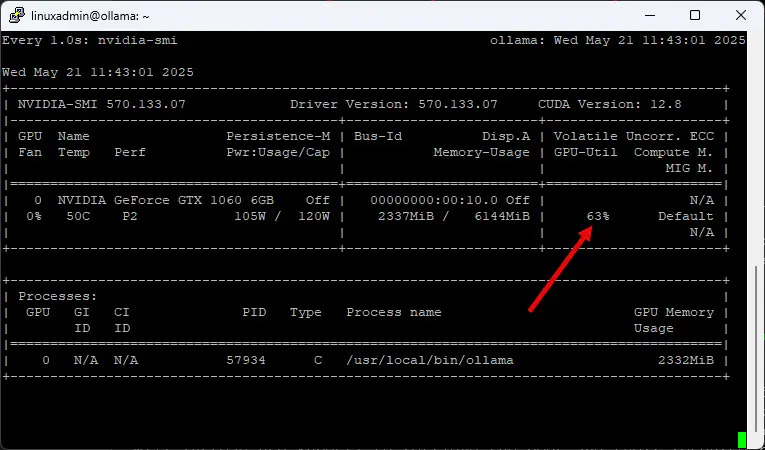
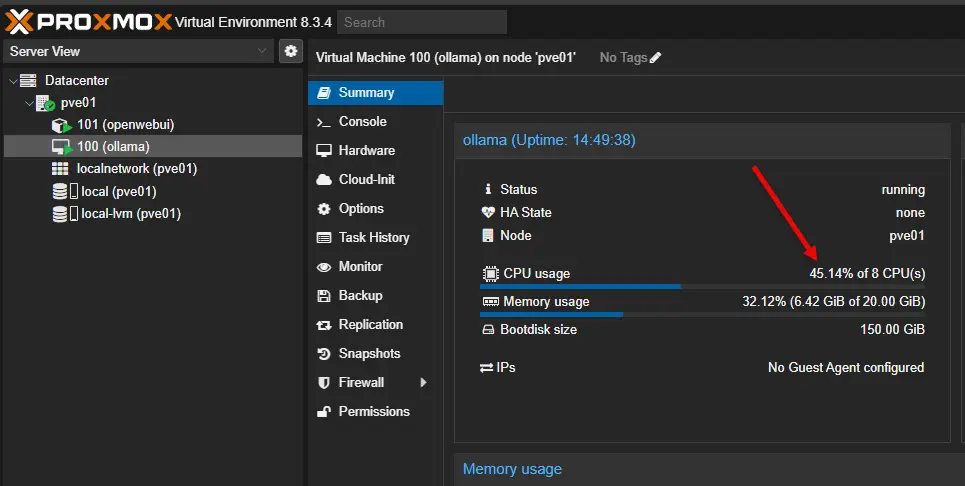
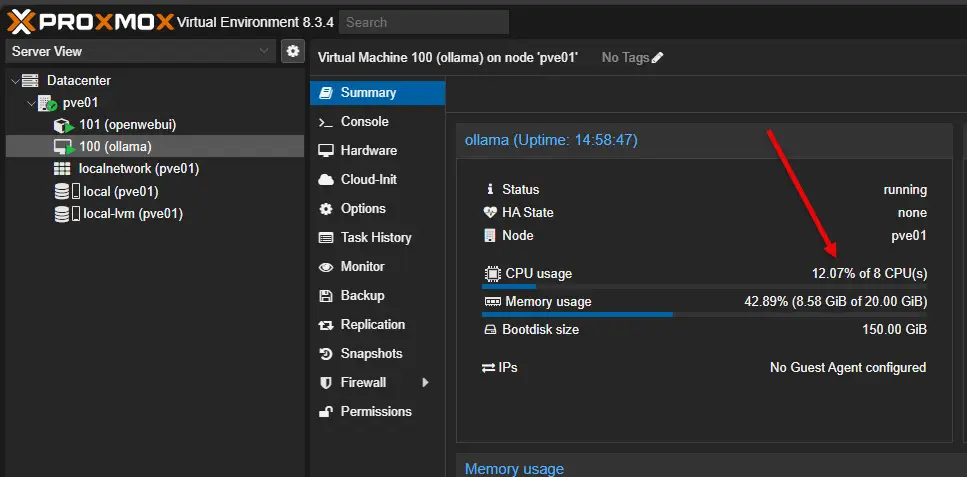
In the Proxmox web UI, this is what I saw with the virtual machine when a chat query was initiated. With 8 vCPUs carved out of the Ryzen 9 7945HX processor, I saw roughly 45% CPU usage in addition to the 60-65% CPU usage.
Different models may offload differently with the old GPU. For instance, mistral:7b fared better in terms of its ability to use the GTX 1060.
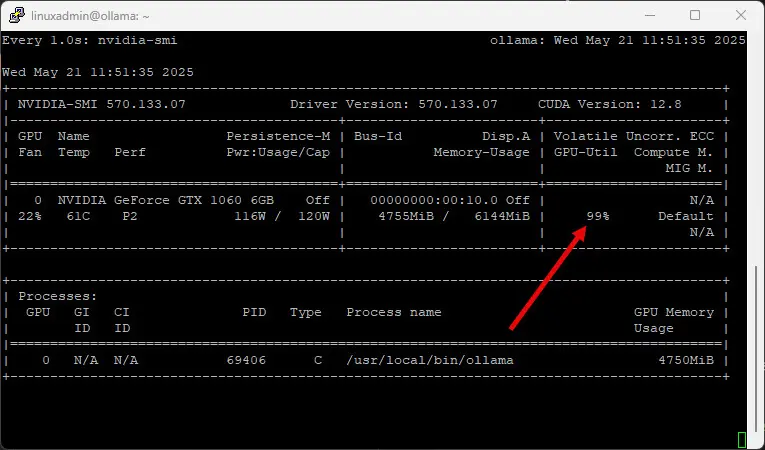
The 1060 with mistral was able to be fully used, and only 12% roughly of the CPUs were used for the VM.
Benchmark Results: Token Generation on the GTX 1060
Performance is what everyone wants to know, so here are the real-world token generation results from OpenWebUI using various models:
- Mistral 7B (q4_0): 27.73 tokens/sec
- Gemma 2B (q4_0): 22.55 tokens/sec
- LLaVA (image + text): ~8 tokens/sec
- TinyLLaMA: ~30+ tokens/sec
Are these numbers blazing fast? No. But for use with short prompts and to start experimenting with AI, they are completely useable.
What Models Actually Fit in 6GB VRAM?
The key limitation of the GTX 1060 is memory. You only get 6GB of VRAM, and that’s barely enough to fit larger LLMs. However, you can still run many models in quantized formats, such as:
- Mistral 7B q4_0 or q5_1
- Gemma 2B q4
- TinyLLaMA or Phi-2
- LLaVA-light for vision tasks
Also, it does have tensor cores or other more modern AI-specific features and capabilities.
How to Optimize AI Workloads on GTX 1060
To squeeze the most performance out of the GTX 1060, there are a few best practices in mind:
- Use 4-bit quantized models
Using formats likeq4_0andq5_1help to offer good balance between performance and accuracy - Avoid loading multiple models at once
You’ll run into VRAM errors quickly with this card. So, keep your workload focused on a single model - Limit context window size
Reducing the number of tokens passed into the model reduces VRAM usage - Use
nvidia-smito monitor memory
This tool is a great way to see how much VRAM is being consumed - Cool your GPU adequately
AI inference can push the card hard, so make sure it’s ventilated well—even if it’s an old GPU.
Why seeing old cards like this work is important
It is great to see old cards like the GTX 1060 still work in terms of local AI. Tools like Ollama and OpenWebUI are allowing users to have the experience of hosting their own large language models and self-host their chat sessions. It also can allow you to reuse old hardware like the GTX 1060 that you might have lying around.
Ultimatiely, it shows that you don’t need to invest in ultra high-end cards to have AI capabilities locally. You can get started with something you already own and many times, that is good enough. The experience with the GTX 1060 was actually very good and performed acceptably.
Being able to experiment with these types of models on commodity hardware makes the GTX 1060 a useful piece of hardware, still in 2025.
Wrapping up
With modern AI models and workloads, it is easy to just assume that old hardware is not going to work. But really, in testing a card as old as the NVIDIA GTX 1060, it shows that cards like these still have some life left in them, even for AI workloads. Due to quantization and better tools like we have now today with running LLMs locally, the barrier to entry for AI is much lower than one might expect.
So, long story short, if you have a GTX 1060 with 6GB VRAM, you can absolutely give it another shot at life as an AI card in a home lab or home server system. It’s not going to win any speed contests, but it works. And it works acceptably with a quite good experience. Let me know in the comments if you are using something as old as the GTX 1060 for playing around with AI at home.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author