
There is definitely a checklist of things that I think are good to mention when it comes to backing up things in the home lab. We all know about “backups” but this term is fairly vague and there can be assumptions made as to what that actually means or includes. Most will setup automated backups for their virtual machines and then it stops there. However, when it comes down to it having good “backups” includes more than just the backups of your virtual machines. Let’s take a look at the 10 things you should backup in your home lab but probably aren’t currently.
1. Configuration files
Have you ever spent hours tweaking nginx.conf, your .bashrc, or the YAML files for a Docker service? If you have, then you know how valuable those small text files can be. If you were to lose one of them, it could possibly mean losing weeks of work tweaking and tuning.
Config files are an important part of how everything works in the home lab and production environments. They live all over the place, depending on the application or service. However, typical locations include /etc, /opt, or sometimes things are found inside the user’s home directory. These files are extremely important and can mean tons of pain trying to recreate things from scratch.
Make it a habit to back up your critical configuration directories automatically. Examples include:
- /etc/ for system and network config locations
- /opt/ for custom apps and Docker stacks
- /usr/local/bin/ for scripts you may have installed
- /root/ or /home/username/ for user-specific configurations, .bashrc, etc
You can even create a BASH script that runs similar to the below that will run and grab the configs and store these in a backup mount that you have mounted:
tar -czf /backup/configs-$(date +%F).tar.gz /etc /opt /usr/local/bin /home/usernameMake sure this mount is stored outside of the existing server environment like on a NAS or cloud location. I am also a huge advocate of storing config files in a Git repo. Git is a great way to store and version text config files. I store text files, YAML files, shell scripts, and anything else that makes sense.
Do yourself a favor and keep your Docker compose files in Git. This is a great way to learn the git workflow and also to have a way to easily roll back changes or specific versions.
2. Container volumes
A huge misconception, especially among home lab beginners just getting started running Docker containers, is that the container “image” contains the data. However, after you respin your first container that you have some configuration in as a beginner and realize you just lost everything because you didn’t have persistent storage setup, you learn a pretty valuable lesson.
To have persistent data with Docker containers, most use simple BIND mounts on their Docker container host. This allows you to store internal directories to the container in side a folder that is just exposed in your file system.
However, the image doesn’t contain the data. These Docker volumes may contain databases, app data, logs, uploaded files, etc.
You can create a manual volume backup with a script that looks like the following:
docker run --rm \
-v my_volume:/data \
-v /backup/docker:/backup \
alpine tar -czf /backup/my_volume-$(date +%F_%H-%M-%S).tar.gz -C /data .However, I like using tools like Duplicati to back up my Docker container volume data. Or, you can also use a backup solution like Veeam and install the Linux agent and have file level access to the Docker host this way. This is necessary if you are using software-defined storage like Ceph. If you backup the virtual machine, including the disks, it won’t be able to grab the data that is contained in your Ceph or CephFS volume. Do keep this in mind!
3. Reverse proxy data
Another configuration file that you want to grab is any reverse proxy configuration. I view these like my Docker Compose stacks and store these inside of Git. Keep in mind that your reverse proxy configuration is A LOT of getting your apps back up and running. These manage SSL certs, route traffic, and storage config data.
Think about this. Even if you have all of your container volume data backed up. What if you lose your entire reverse proxy configuration? That would be bad. If you are like me, I cringe thinking about having to recreate all of the configuration I have stood up in Traefik.
If your reverse proxy dies, you could lose every certificate and have to reconfigure each domain and subdomain manually. That can be a painful process if you host multiple services under custom DNS names.
For Nginx Proxy Manager users, make sure to back up the /data directory you have BIND mounted for your NPM container. For Traefik, keep copies of your configuration files and the acme.json file that contains Let’s Encrypt certificates.
Example with Traefik:
sudo tar -czf /backup/traefik-backup-$(date +%F).tar.gz \
/etc/traefik/ \
/opt/traefik/ \
--exclude='*.log' \
2>/dev/null || echo "Some paths may not exist"And of course, definitely put your Docker compose file for Traefik in Git.
Restoring these files later can instantly rebuild your routing and certificate setup.
4. DNS zone data
If you host your own DNS server using something like Pi-Hole, AdGuard Home, or Unbound, backing up your config and zone files is a smart thing to do. I like keeping a copy of my unbound.conf file in Git. I have a CI/CD pipeline that runs each time I make a change to the config file that respins the container once the config file is changed from the CI/CD process.
If you use Bind9, the files are usually located in /etc/bind/ and /var/lib/bind/. For Pi-hole and AdGuard Home, you can export your settings from their web UI or automate the backup using their command-line tools.
For example, you could do something like the following:
sudo mkdir -p /backup/pihole && pihole -a -t && sudo cp /var/www/html/admin/pi-hole-teleporter_*.tar.gz /backup/pihole/ && sudo rsync -av /etc/pihole/ /backup/pihole/etc-pihole/Back these up weekly. You’ll be thankful that you did the next time your container or VM doesn’t boot.
5. SSH keys
Your SSH keys are another important thing to backup in your home lab. These are super important files that if you lose them, you likely will be locked out of your own systems with no way to recover.
Backup your SSH keys in a safe place that is secure. Preferably, use a purpose-built place like Hashicorp Vault, or Doppler. You want to always use encryption and protect your backups with a passphrase or a password manager like Bitwarden or KeePass.
Here are the usual locations for keys:
- ~/.ssh/id_rsa and ~/.ssh/id_rsa.pub
- ~/.ssh/config for connection aliases
Below is an example script for backing up your SSH keys:
tar -czf - ~/.ssh | gpg -c > /backup/ssh-backup-$(date +%F).tar.gz.gpgThen move this to a secure drive or cloud bucket.
6. Prometheus metrics and Grafana dashboards
Monitoring with open-source solutions like Prometheus and Grafana also take a lot of time and effort to get things just right. While monitoring may not be the first thing you want to recover if something bad happens, eventually you will.
If you are using Prometheus it stores its metrics database in this location: /var/lib/prometheus. Grafana stores its dashboards in /var/lib/grafana.
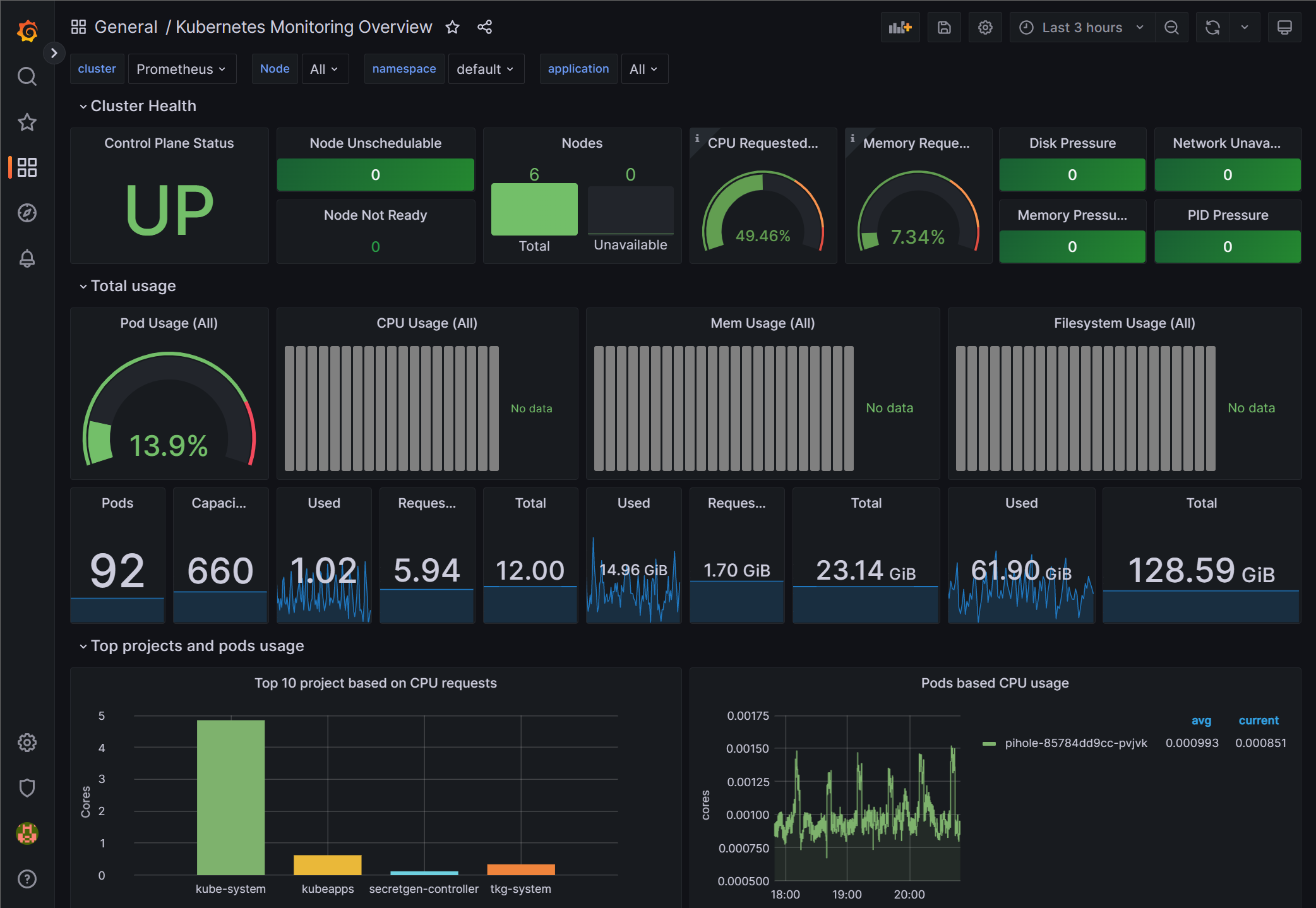
To back these up, stop the containers and archiving the data directories. Or for a more seamless method, mount them as named volumes and back those up automatically like other container data. Below is a production-ready script for backing up Prometheus:
#!/bin/bash
set -e
PROMETHEUS_URL="http://localhost:9090"
PROMETHEUS_DATA_DIR="/var/lib/prometheus"
BACKUP_DIR="/backup/prometheus"
RETENTION_DAYS=7
TIMESTAMP=$(date +%F_%H-%M-%S)
mkdir -p "$BACKUP_DIR"
echo "Starting Prometheus backup at $(date)"
# Create snapshot
echo "Creating snapshot..."
SNAPSHOT_NAME=$(curl -sS -XPOST ${PROMETHEUS_URL}/api/v1/admin/tsdb/snapshot | jq -r '.data.name')
if [ "$SNAPSHOT_NAME" = "null" ] || [ -z "$SNAPSHOT_NAME" ]; then
echo "ERROR: Snapshot creation failed. Is --web.enable-admin-api enabled?"
exit 1
fi
echo "Snapshot created: $SNAPSHOT_NAME"
# Backup snapshot
echo "Compressing snapshot..."
sudo tar -czf "${BACKUP_DIR}/prometheus-snapshot-${TIMESTAMP}.tar.gz" \
-C "${PROMETHEUS_DATA_DIR}/snapshots" "${SNAPSHOT_NAME}"
# Backup configuration
echo "Backing up configuration..."
sudo tar -czf "${BACKUP_DIR}/prometheus-config-${TIMESTAMP}.tar.gz" \
/etc/prometheus/
# Cleanup old snapshot
echo "Cleaning up snapshot..."
sudo rm -rf "${PROMETHEUS_DATA_DIR}/snapshots/${SNAPSHOT_NAME}"
# Remove old backups
echo "Removing backups older than ${RETENTION_DAYS} days..."
find "${BACKUP_DIR}" -name "prometheus-*.tar.gz" -mtime +${RETENTION_DAYS} -delete
# Show backup info
echo "Backup completed successfully!"
echo "Files created:"
ls -lh "${BACKUP_DIR}/"*${TIMESTAMP}*
# Calculate backup size
TOTAL_SIZE=$(du -sh "${BACKUP_DIR}" | cut -f1)
echo "Total backup directory size: ${TOTAL_SIZE}"Grafana dashboards can also be exported as JSON from the web interface for version control or backup to GitHub using a script like below:
#!/bin/bash
GRAFANA_URL="http://grafana.local"
API_TOKEN="YOUR_TOKEN"
BACKUP_DIR="/backup/grafana"
mkdir -p "$BACKUP_DIR"
TIMESTAMP=$(date +%F_%H-%M-%S)
# Get all dashboard UIDs
DASHBOARD_UIDS=$(curl -sS -H "Authorization: Bearer ${API_TOKEN}" \
"${GRAFANA_URL}/api/search?type=dash-db" | jq -r '.[].uid')
# Backup each dashboard
for uid in $DASHBOARD_UIDS; do
echo "Backing up dashboard: $uid"
curl -sS -H "Authorization: Bearer ${API_TOKEN}" \
"${GRAFANA_URL}/api/dashboards/uid/${uid}" \
> "${BACKUP_DIR}/dashboard-${uid}-${TIMESTAMP}.json"
done
echo "All dashboards backed up to ${BACKUP_DIR}"7. Cloud credentials and API tokens
Another big one is cloud credentials and API tokens that you need to keep safe. If you use automation tools like Terraform, Ansible, or other CI/CD pipeline tools, your API keys and credentials are extremely important.
Think what pain you would be in for if you restored your infrastructure after a disaster but realized you didn’t have your credentials for AWS, Cloudflare, or Github.
You can store these types of credentials in a secure way using:
- A secrets manager (Bitwarden, Vaultwarden, or HashiCorp Vault)
- Encrypted .env files backed up to offsite storage (also check out my write up on Doppler which has a free version)
- GPG-encrypted text files
For example:
gpg --symmetric --cipher-algo AES256 -o /secure-backup/aws-credentials-$(date +%F).env.gpg aws-credentials.env && shred -u aws-credentials.envNever store credentials in plaintext, even if it’s in your home lab as bad things can happen!
8. VM templates
If you are like me, I use VM templates to spin up new virtual machines and Docker container hosts. Think about backing up your images as well to allow these to be recovered as part of your restore process.
You’ve probably built a few “golden images” or base templates for your virtual machines. These are worth backing up because they represent a clean, tested starting point for your builds.
Below, is a production ready Proxmox template backup script that you can use to backup your PVE templates in the home lab:
# Backup VM template
vzdump <vmid> --dumpdir /mnt/pve/backups --mode snapshot --compress zstd
# Backup LXC container template
vzdump <vmid> --dumpdir /mnt/pve/backups --compress zstd9. Application secrets and environment files
When you stand up self-hosted apps, often, we use .env files to store secrets and other variables with sensitive information. It is best practice not to include these in any type of Git repository as you are asking for problems from a security standpoint. However, these files are also critical to your infrastructure provisioning.
What do I recommend on this front? Don’t use sensitive .env files if you can help it. A better approach is to use something like Infisical or Doppler to store away your sensitive data. That way you have it safely stored in your own secure location that doesn’t reside locally.
10. Infrastructure documentation and diagrams
Your home lab might be simple now, but as it grows, you’ll forget how everything connects. This is so easy to do especially as things grow and evolve and you add things and remove things. Be sure to back up your documentation. Of course, having your docs in a Git repo helps to solve this issue as you already have it tucked away. I have Gitlab running self-hosted in my home lab, but then I have my important repos mirrored to Gitlab cloud (free). This gives me piece of mind knowing it is versioned and committed, and also stored in two different location.
Your documentation should include things like:
- Network diagrams
- IP assignments
- VLAN maps
- Notes on configurations or credentials
- Text-based runbooks for restoring key services
- Diagrams of how things look: Check out my post on visualizing docker compose code (yes you can do that!) Visualize Your Docker-Compose with Mermaid + docker-compose-viz.
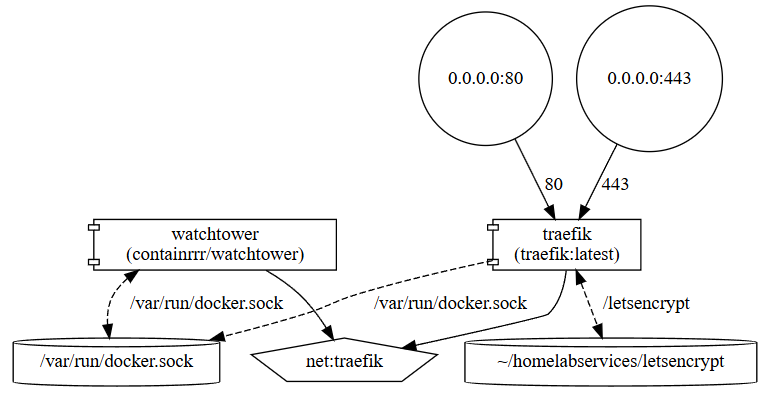
It may sound like it isn’t necessary, but this kind of documentation becomes even more important when you’re recovering from data loss or trying to piece things back together.
Wrapping up
The perfect home lab backup strategy is kind of like security, it takes layers. You can’t just depend on one specific thing and feel 100% secure. In your home lab, add to the necessary virtual machine backups with other things like backing up your config files, container volumes, proxy data, DNS zone data, SSH keys, Prometheus and Grafana dashboards, cloud credentials and API keys, container and VM templates, application secrets, and even your documentation. If you cover all of these things, you will be well on your way to making sure you can recover no matter what happens in your home lab. Let me know what you are backing up and if there is something crucial that you make sure you have on your list.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author




Honorable mention is a bare metal, up to date image of your primary workstation or laptop you do all your admin, design, management, etc from.
Trying to do this from a system you don’t normally use can get painful quickly for a multitude of reasons, and there is nothing more infuriating than not being able to repair your main workstation because some rando issue borked a server, vm, router, etc in your lab you need but you don’t have the software, ssh key, or creditial manager loaded on the crap laptop you pulled out from under your bed. Now your stuck updating and loading software on a machine that you will likely never use again.
Having a bare metal restore option gives you a way to get back underway in just an hour or two (depending on what you’re storing) if your OS nukes itself or you lose a drive. I use acronis to image mine weekly to a detecticated local HDD just for this purpose. Lots of other free and paid options out there too.i just like acronis becaus it makes it easy to migrate my image to different hardware or a VM if required. Be sure to encrypt your images too! simple password protected symmetric key is good enough for the home user as long as your password is good and your using aes.
Michael,
This is spot on! Definitely an area that often gets forgotten. I remember having a similar experience when the power went out for me. I didn’t really have shutdown automation in place and had a laptop that I normally didn’t use that I was trying to shut everything down from. It was a pain. I didn’t have host entries in place or other things that I normally had on my mgmt workstation. So, definitely have felt this often forgotten area of disaster recovery.
Brandon