
We have exciting times to be able to run a home lab with all the automation, AI, and other tools available to us to use. In fact, I am more excited about running automation in the home lab than ever before. Even if you are not a developer, DevOps professional, cloud engineer, etc, with AI and tooling, most of us can figure out what we need to successfully automate and run a home lab that is fully automated, and self-healing. In this post, we will consider how we can automate and self-heal certain things in the home lab, tools we can use, and practical use cases.
Why home lab automation matters
The goal of home lab automation is pretty simple. You want to use it to create a self-healing environment that can detect problems. But not just that. You want it to be able to take corrective actions, and bring itself back online in an automatic way. You can do this with the right mix of monitoring, automation, and workflows, you can build a lab that runs 24/7 without you constantly checking in.
What a self-healing home lab really means
Self-healing infrastructure means your systems constantly monitor themselves. They can detect failures, and recover automatically. It’s about shifting from a reactive to a proactive mindset. When a service fails, your automation doesn’t wait for you to notice. It gets busy and runs the fix as soon as possible.
For example, what if a Docker container crashes. Monitoring tools like Netdata or Prometheus can the issue and trigger an alert. That alert then kicks off an automated workflow in Ansible, Node-RED, or n8n to restart the container. Within seconds, the service is back online. You can then get notified that something went wrong and that it’s already fixed. That’s really the essence of what self-healing can do for you.
Core building blocks of a self-healing lab
So what are the core building blocks of a self-healing home lab? I think these can be broken up into the 4 categories below:
- Monitoring
- Alerting
- Remediation + AI
- Validation
Note what each of these includes:
Monitoring is where it all starts. Without visibility into your home lab, you can’t automate things effectively. Netdata, Prometheus, and Grafana are perfect for real-time metrics. They can track CPU, memory, disk I/O, container uptime, and service availability for you. Netdata Cloud even adds something they call anomaly detection to help identify issues before they turn into outages.
Alerting is the part of the workflow that makes sure that when something goes wrong, your system can respond very quickly so you don’t have to wait until you find out on your own or when something is down. Grafana’s has an alerting engine built in, the newly reviewed Pulse monitoring for Proxmox and Docker that I checked out has alerting, or Netdata’s built-in notifications can send alerts through email, Telegram, Pushover, or webhook integrations.
Remediation + AI is where automation and even newer, AI, comes into play. When an alert is triggered, you can use tools like Ansible, Node-RED, or n8n to do things to perform recovery actions in an automated way and tying into using a chatbot. This might mean restarting a failed container, rebooting a VM, or power-cycling a host using the IPMI or iDRAC type OOB management connection.
Last step, validation confirms that the issue has been resolved and you no longer have an issue. The same monitoring stack that detected the problem can make sure that everything is once again healthy.
Adding n8n to the automation stack
One of the most awesome additions right now to a modern home lab automation workflow is n8n. It is a self-hosted workflow automation platform that you can use to do things in your home lab. Think of n8n like a system’s engineer, Docker expert, Kubernetes expert and full-time troubleshooting engineer you have available at your fingertips.
Basically, anything that an AI model knows how to do or has knowledge in (which is basically anything related to computers, IT, DevOps, cloud, etc), you can harness to work for you and your home lab. It allows you to create event-driven workflows.
Then you can connect different services, APIs, tiggers, and command line commands. This is similar to what you can do with something like Node-RED. However, n8n has a stronger focus on data flow and integrations.
With n8n, you can build workflows that respond to alerts from your monitoring stack or messages from your automation tools. Let me give you an example of a workflow. Note the following:
- Receive a webhook from Netdata or Prometheus when a container goes down
- Query the Docker API or Proxmox API to confirm the failure
- Execute a recovery step such as restarting the container or VM
- Send a Pushover notification when the system recovers
You can even build conditional logic into your workflow. Take for instance, suppose a host is unreachable. n8n can first try to restart critical containers with SSH. If that doesn’t work, it can then escalate by triggering a Home Assistant automation to power-cycle the node using a Shelly smart plug. Once the host comes back online, n8n can log the entire event. It could even update a Google Sheet with uptime data. Finally, it can send you a post mortem report on what happened and the actions used to troubleshoot and resolve the issue.
The best part about n8n is how flexible it is. You can self-host it as a Docker container and integrate it with almost any API. Check out my full tutorial on how to spin up n8n in Docker here:
The n8n solution has so many components that can make automating and self-healing your home lab extremely powerful. These include the following nodes:
- Scheduling node
- SSH node
- Message nodes (Discord, Slack, etc)
- HTTP Get node
- AI Agents
You can use things like the SSH node to actually SSH into a Linux node you have running and run commands for you:
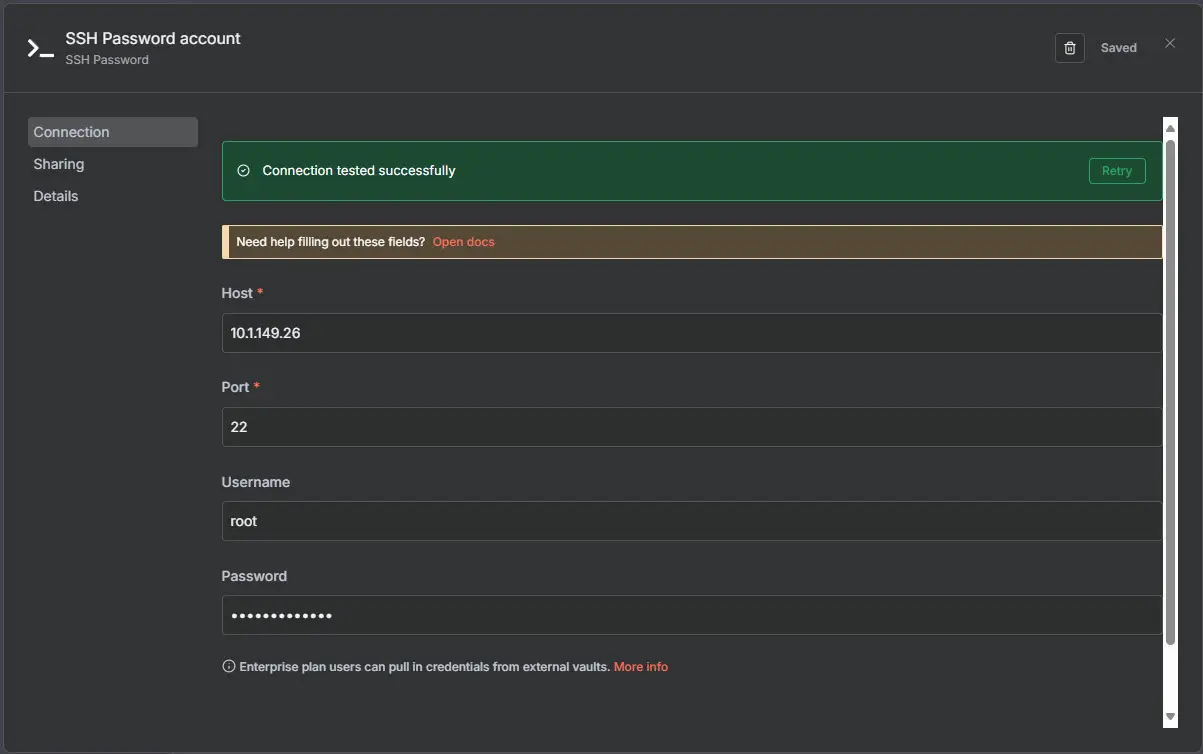
If you haven’t checked it out as of yet, Network Chuck did a really great video walkthrough on using n8n to automate things in the home lab. Check out his GitHub repo here where he includes instructions on how he setup his workflow in n8n: theNetworkChuck/n8n-terry-guide.
An example of one of my workflows
As you all know I have written quite a bit about using GitLab in the home lab. I have several pipelines that run each day doing different things in the home lab. When the pipelines run, they send statuses of the pipelines to a private Discord channel I have on my server.
This is nice in that I can check a single channel and see the statuses of all my pipelines. However, what if AI could do that for me? What if I could setup n8n to have an AI agent check this for me. If there is a failure it can troubleshoot and even kick the pipeline back off for me? That is just what I wired up in an n8n workflow.
On the canvas, here is my workflow:
- It triggers on a schedule
- It gets messages from my Discover server specific channel
- I edit the fields to return the data and name the fields what I want
- AI Agent processes the messages and looks for anything other than “Normal”, so like Warning, or Error
- It uses either a GitLab “get” or GitLab “post” to get details of pipelines or kick off the pipeline to retry it
- Structured output parser cleans up the output data
- The “If” function only sends messages that are anything other than “Normal” to Discord
- Discord of course sends the result message of what it found and Actions taken
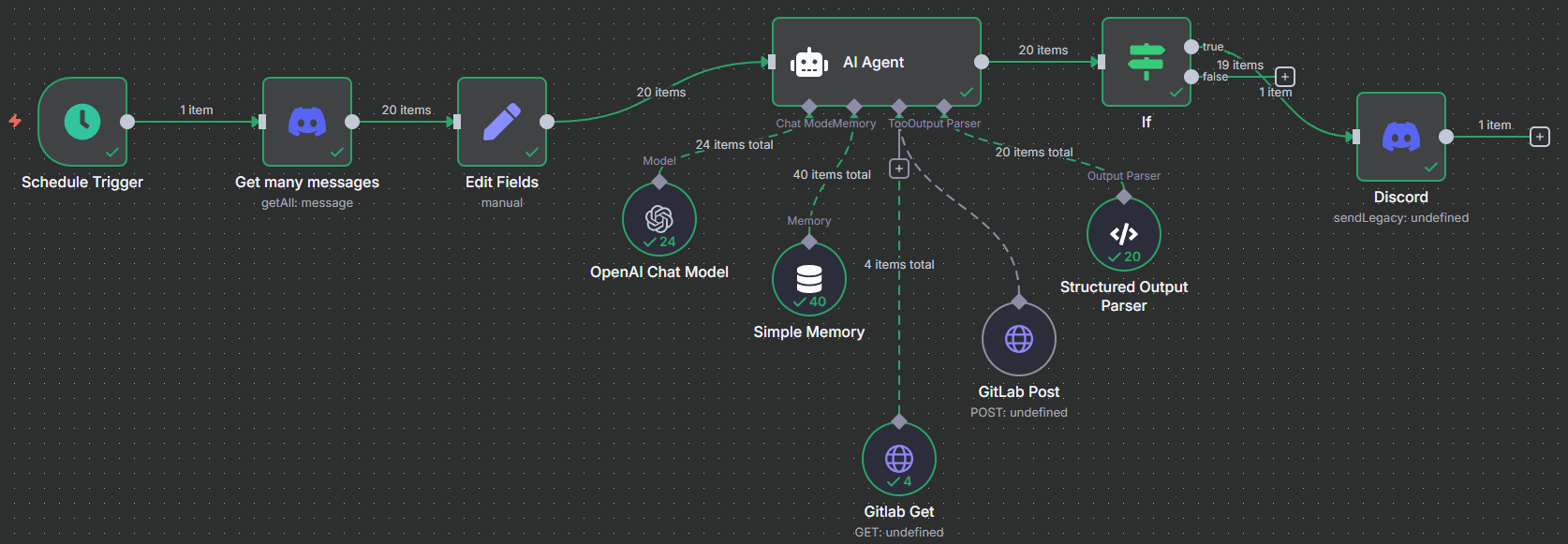
I get a result of the processing of looking through my jobs, etc:

Using something like Home Assistant to manage physical hosts and devices
The physical side of a self-healing home lab is just as important as software automation. If you are using something like Home Assistant, you can integrate smart relays or outlets like Shelly or TP-Link devices to remotely power-cycle hosts. For example, if your monitoring system detects a node is offline for more than two minutes, n8n can send a command through Home Assistant to reboot the device.
Containers and virtual machines
Most home labs run services and apps that reside in either virtual machines or containers. Out of the box Docker supports restart policies. This helps to make sure that containers automatically restart if they crash or the host comes back up after a crash.
Take for instance the restart policy stanza in the Docker compose configuration for Pangolin below:
services:
pangolin:
image: ghcr.io/pangolin-proxy/pangolin:latest
container_name: pangolin
restart: always
ports:
- "80:80"
- "443:443"
volumes:
- /home/linuxadmin/homelabservices/pangolin:/etc/pangolinDocker Swarm and Kubernetes make this even more powerful by continuously monitoring service health and rescheduling workloads on healthy nodes if these fail.
In terms of updating, I already use automation tools like Watchtower and Shepherd to update containers in the home lab environment. Be sure to make this a part of your automation and self-healing from the standpoint that keeping the latest container images pulled will help to minimize problems or security issues down the road.
Check out my post on Watchtower and Shepherd here: Watchtower Docker Compose – Auto Update Docker containers.
On the virtualization side, Proxmox has several high-availability features built into the platform. When these are configured, host or VM failures can be detected and workloads can be automatically restarted on another node. If you don’t have a full HA cluster, you can still use the Proxmox API with n8n. You can also opt for something like Ansible to monitor and restart VMs programmatically using infrastructure as code.
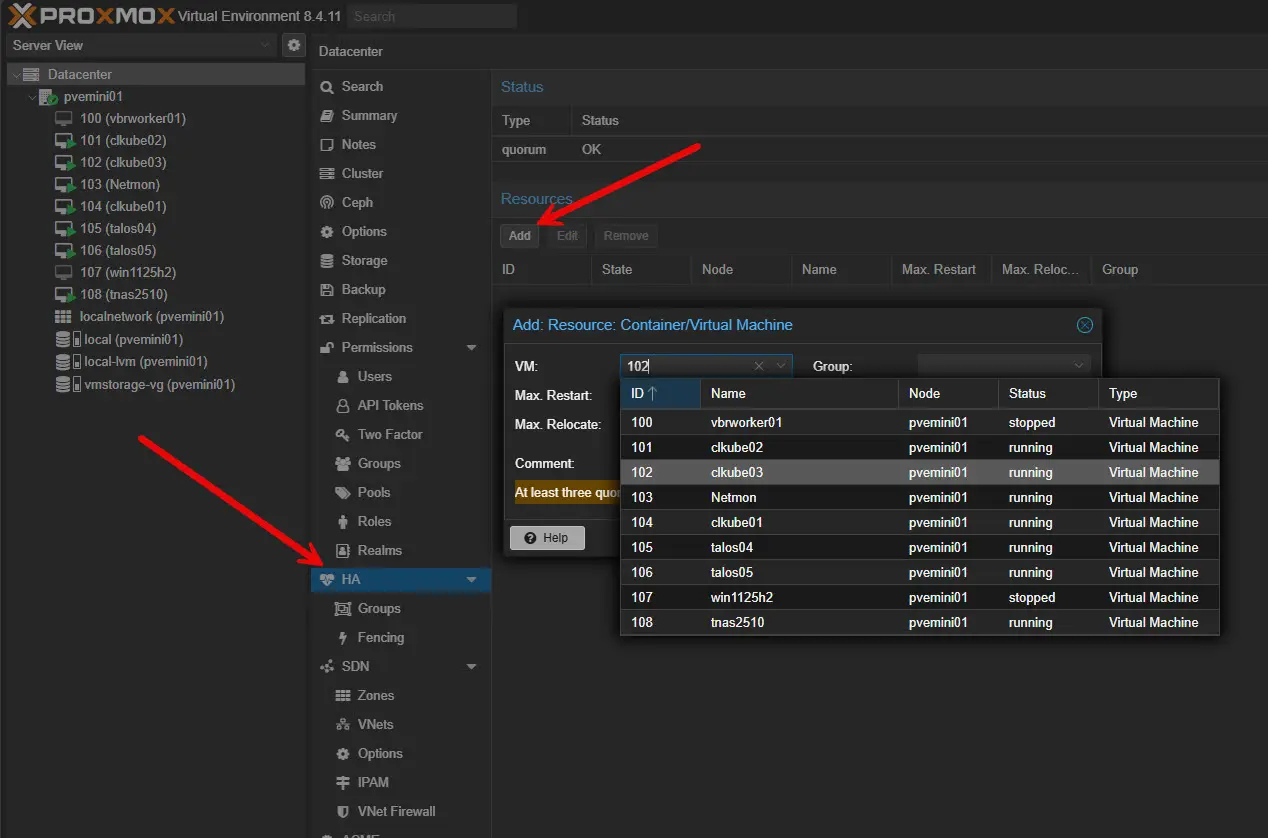
Check out my Proxmox HA configuration guide here:
Safety nets and my recommendations
Automation can be powerful, especially if it uses AI. Always log every automated action so you can track what happens with actions taken. Add things like cool-down timers to prevent loops where a service restarts endlessly due to not enough time being given between health checks after a remediation. Test new automations on non-critical workloads before using them on your production containers or VMs in the home lab or true production environments.
Predictive healing and smarter monitoring
With the new AI-driven monitoring and other things we are seeing possible now with generative AI, predictive monitoring and healing are now possible in ways they were not before. Tools like Netdata Cloud are already building in AI-driven anomaly detection. AI is so much better than us as humans at recognizing unusual patterns that we may not pick up on, like unusual traffic patterns or spikes in disk latency. These can alert you early.
Then you can combine predictive insights with tools like n8n to trigger proactive recovery or remediation like moving workloads, or freeing up resources before these fail.
Wrapping up
A self-healing home lab means different things to different people. However, one thing is for sure, we know in 2025 moving into 2026 have the tools along with AI and other solutions like n8n to do things we could have never done before. I am starting out small and simple with my AI-driven workflows in n8n to dip my toes in the water of automation. However, I can see there are just endless possibilities to all of these admin tasks now with AI leading the way to proactive and self-healing administration. What about you? Have you started to play around with n8n in your home lab? What other self-healing automation are you using?
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author




I am getting my n8n instance setup to play around with. Can’t wait to see what I can do with it
So you followed network chucks video he posted a few says ago and don’t give him credit?
You didn’t read the blog did you? Lol