
There is no question that AI tools and self-hosted AI is becoming one of the most popular self-hosted applications in home labs at the end of 2025 and beyond. Artificial intelligence used to be something you only heard about living in massive data centers. However, with the explosion of open-source distilled models and GPU acceleration, it is easier than ever to self-host your own private AI. Let’s take a look at the best self-hosted AI tools you can actually run in your home lab.
Why self-hosted AI is a big deal
More and more we are hearing about privacy and other data dangers from sending your data into cloud-hosted AI prompts. By hosting your own models locally, you have full control over your own data and your chats. No one else is going to have access to that.
Also, if you are like me, I didn’t have much experience with AI and AI models before experimenting around with things in the home lab. by hosting your own models you learn how inference works, how important GPU memory is and how it relates to your LLM performance and you can also wire in your local LLMs and private AI with other tools like Ollama and n8n.
Most of all, I think private AI and self-hosting your own AI tools is a lot of fun. All of the cool things that are possible to be self-hosted these days would have been science fiction only a few years ago.
Ollama
Let’s start with what I consider to be the most popular self-hosted AI tools today and that is Ollama. It is a lightweight and easy to install/use tool that lets you run the large language models (LLMs) locally. It is the “engine” for the LLMs to run on top of.
Ollama can pull and manage models locally after these are pulled from Huggingface or another source. What types of models does it give you access to? You can run things like:
- GPT-OSS
- Gemma
- Llama 3
- Phi 3
- Mistral
- Deepseek
- and many others
Ollama spins up a local API endpoint that allows other tools like OpenWebUI (see below) to interact with it. If you are using Docker or Promox LXC containers, Ollama is super easy to deploy and it supports GPU acceleration out of the box with NVIDIA or AMD GPUs. You can also fall back to using CPU inference if you don’t have a discreet graphics card.
So, I am listing Ollama first since it can be the perfect backbone so to speak of your local private home lab AI setup. Once you have Ollama running a model, you can then build on top of this and tie in your other AI-driven solutions to it.
services:
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama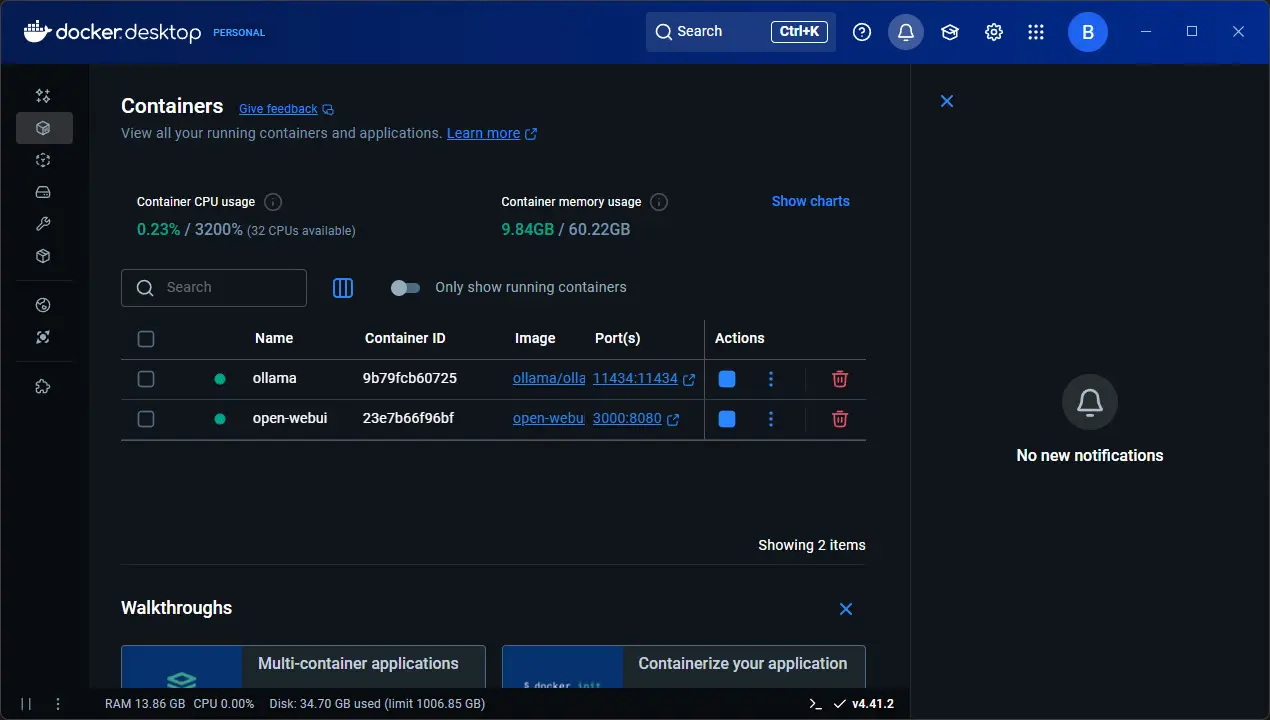
OpenWebUI
So, now on to the next solution in our list. This is OpenWebUI. Even though Ollama is the model engine, you need the tool that allows you to interact with the model engine using a GUI and that is OpenWebUI.
OpenWebUI has a very modular design about it that allows you to not be locked into a specific model. Even though it “looks” like the ChatGPT interface, you can run any of the open source models, include Google and others. So, no vendor lock in.
It connects to Ollama’s API and makes it simple to select a model. You can also set parameters, and start chatting right from your browser. From OpenWebUI it allows you to select and download along with manage the models you want to run and have already downloaded. With it, you have complete chat history, custom instructions, prompt templates, and even image generation if you hook up compatible models.
Combining OpenWebUI with Ollama gives you a full self-hosted ChatGPT alternative. And, it gives you one that lives entirely inside your home lab. Take a look at the quick and easy docker compose code to get up and running with OpenWebUI in docker.
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main
ports:
- "3000:8080"
volumes:
- ./openwebui:/app/backend/data
depends_on:
- ollaman8n
The n8n solution is one that I have been working with A LOT lately. It is one of the most useful tools that you can spin up in your lab environment. With just a bit of time, you can wire up just about anything you can think up using Agentic AI and make it work for you. You get really cool workflow automation that reminds you a lot of something like Zapier or Make. However, this one runs completely locally in the community edition.
With n8n, you can create automations that query Ollama for summaries, use the OpenAI or Hugging Face APIs for advanced model outputs, and you can even call external tools like Docker containers. There are also network tools like SSH sessions, or webhooks that can do many of the things that we would have had to do manually or create intricate scripts before n8n.
As a quick and easy example, you could build an automation where every new RSS article from FreshRSS that you also self-host, gets summarized by Ollama and then posted to your Mastodon account or sent via email. You could also have a daily job that analyzes your log files in the home lab, looks at patterns, and it also sends a daily summary of anything that needs attention to your dashboard.
See my in-depth walkthrough on how to setup n8n in my post here: Automate Your Home Lab with n8n Workflow Automation and AI.
LocalAI
Another project to get familiar with is LocalAI. It is another tool that makes running local models extremely simple. Unlike needing to install Ollama and OpenWebUI, LocalAI is one container for both the model management and the web UI. It uses Ollama underneath the hood. So, from that perspective it is much easier and more efficient to stand up.

It also supports both CPU and GPU acceleration. It is just a single Docker run command in something like Docker Desktop, and can handle models for text and also image generation. LocalAI is a great solution for home labbers who want to use self-hosted AI in their environments.
Also, It can run a lot of different models from Hugging Face, GGUF files, and quantized versions of many popular LLMs. Note the following command to get it up and running:
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12AnythingLLM
AnythingLLM is a tool by a company called Mintplex Labs. It is an all-in-one platform that has a chat interface, also document interaction, and RAG (retrieval-augmented generation) capabilities. AnythingLLM also integrates tightly with Ollama and OpenAI, along with other backends. However, you still get full control over your data.

Unlike the other tools that run in Docker containers, this tool is like LM Studio in that it is a client install that you install on your workstation. In my opinion, this is both a pro and con. I love the flexibility and ease of Docker containers, but also, you don’t have to worry with installing Docker, etc with the installer. So this is a pro or a con depending on how you look at it.
The really cool things about this tool is that it allows you to upload things like PDFs, markdown files, or sync docs from a GitHub repo. It can then create an index of the data locally and use your locally hosted LLM to reference your own content. Then it can answer questions about it.
It’s a great way to build a private “ChatGPT for your home lab” or “AI documentation bot” that runs inside your home lab.
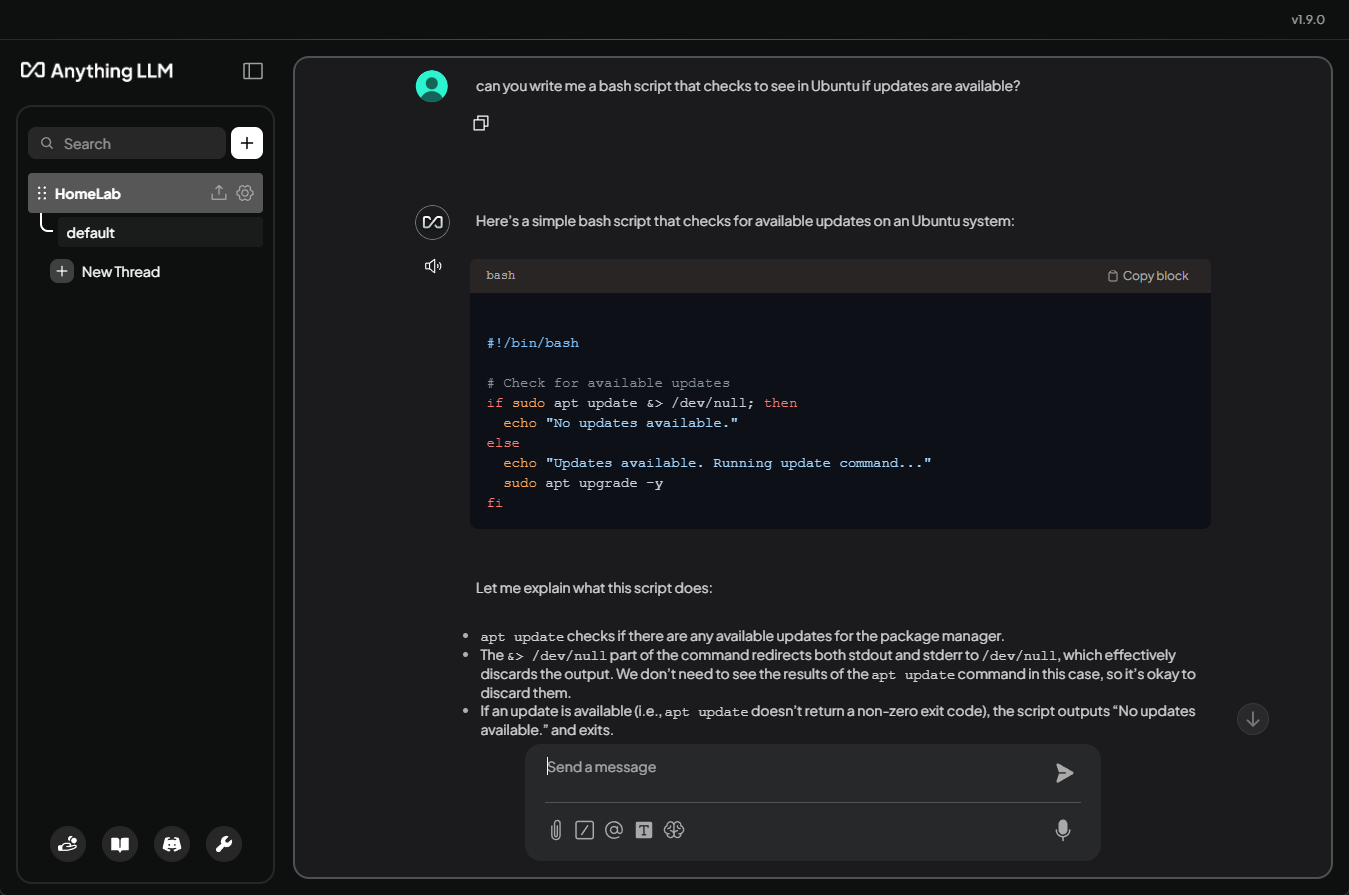
AnythingLLM has a very polished interface. It also includes things like role-based user access, and integrations for webhooks. This makes it easy to connect with tools like n8n or FreshRSS.
Support for NPUs
This is late breaking in the September 2025 release, but Anything LLM can now make use of the NPU in Snapdragon-powered Surface X devices. By default, on Windows ARM64 devices that have the Snapdragon X Elite chipset, AnythingLLM, as of version 1.7.2 can download and run LLMs on the built-in NPU. The developer notes this results in about a 30% performance boost in RAG operations.
Keep in mind in general that NPUs aren’t able to be utilized by most local AI tools. So this is nice to see from AnythingLLM. Do check out my post here to give you some context on NPUs with local AI: NPUs in Mini PCs are Worthless for a Home Lab, Here’s Why.
Whisper and WhisperX
The Whisper and WhisperX projects are for those that want speech to text capabilities. The Whisper project was developed by OpenAI. It is a speech-to-text model that is very accurate. It is even good at the transformation when you have noisy audio.
You can run this locally to do things like transcribe YouTube videos, podcasts, or if you want to feed it your own meeting recordings without sending data to a cloud provider. These are just a few examples of what you can do.
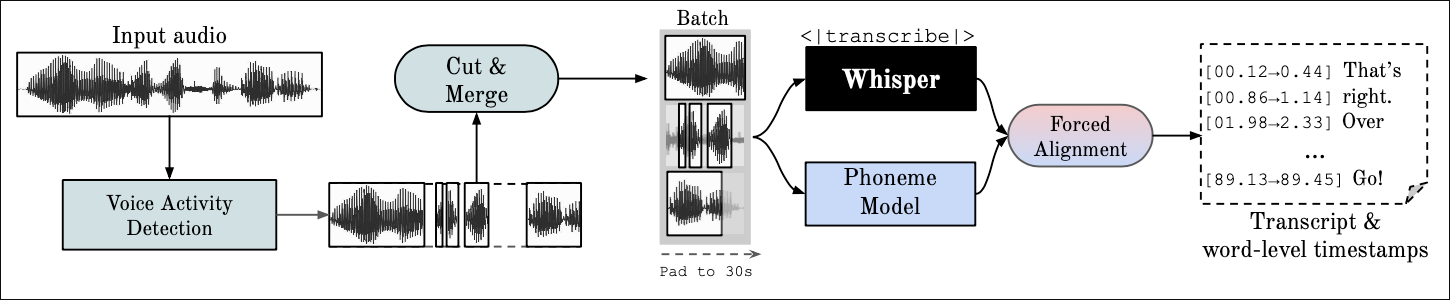
The WhisperX project builds on Whisper as it adds better and faster GPU inference and automatic alignment for timestamp purposes. These can be deployed in Docker containers and create a fully automated transcription pipeline.
Think about the possibilities of using Whisper or WhisperX with n8n to transcribe audio files you upload automatically and summarize them with Ollama. This allows you to use your home lab for local AI transcription and summaries.
Stable Diffusion WebUI
If you are into generating images with a local AI setup, this is where you will likely run across a model called Stable Diffusion. It is still one of the best image generation models you can run on your local setup. Also, it is made even better with the next project I want to highlight. It is AUTOMATIC1111’s Stable Diffusion WebUI. It makes Stable Diffusion super easy to use.
You can run it in Docker, or you can directly run it on your workstation with GPU acceleration. It can generate incredible artwork, thumbnails, or even textures for 3D projects. Stable Diffusion WebUI also supports things like ControlNet, LoRA fine-tuning, and image upscaling.
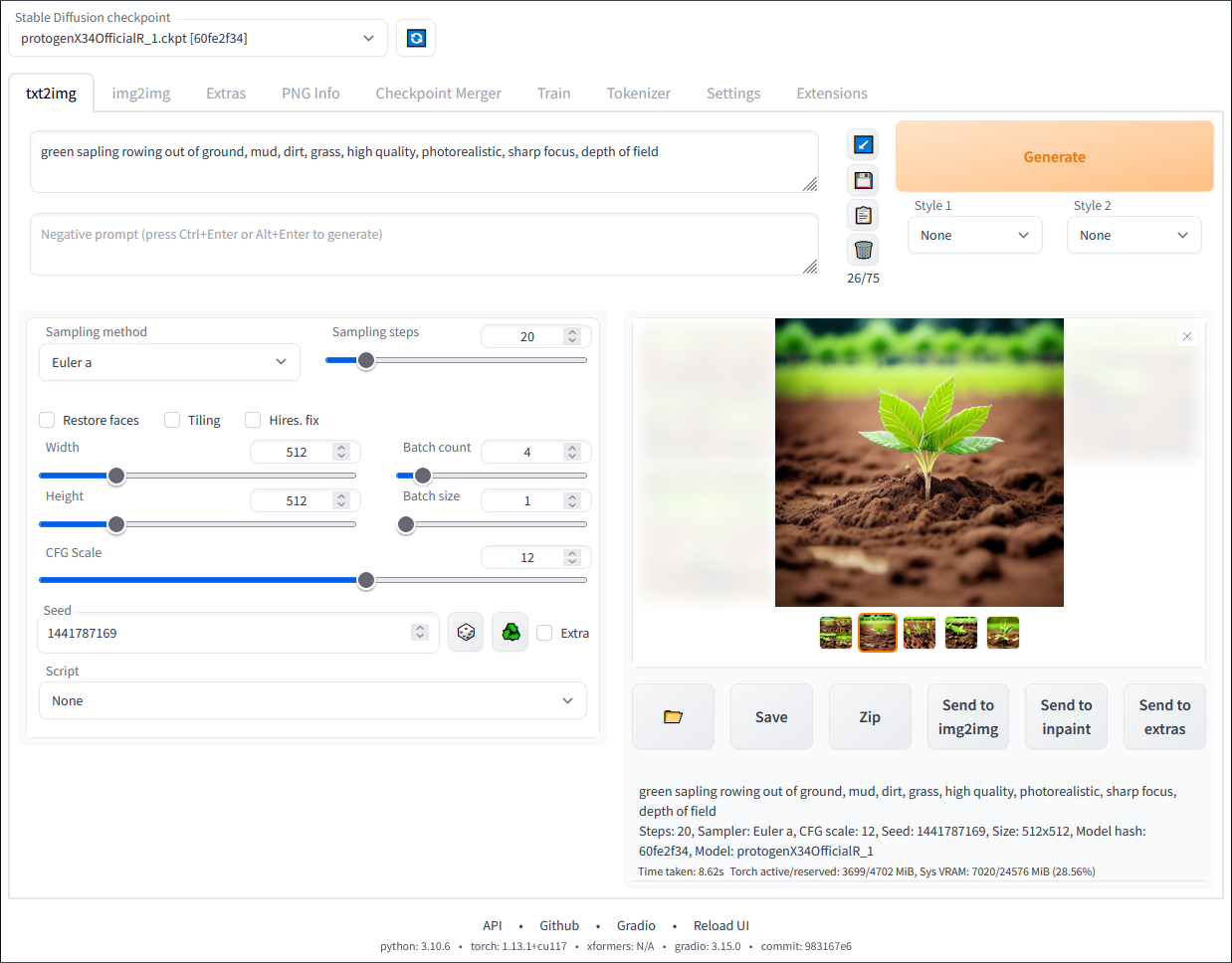
For the home lab crowd, Stable Diffusion can be integrated into your automations for things like generating blog post images if you are a content creator or creating AI-assisted documentation visuals.
PrivateGPT
PrivateGPT is a privacy-first implementation of a chatbot that can run entirely in your self-hosted setup. You can feed it documents and then have it answer questions about them without sending anything into the cloud.
It does this by using a combination of Ollama or LocalAI and also a database to then do retrieval-augmented generation (RAG). If you want to query knowledge bases or personal document stores and keep your tech PDFs private.
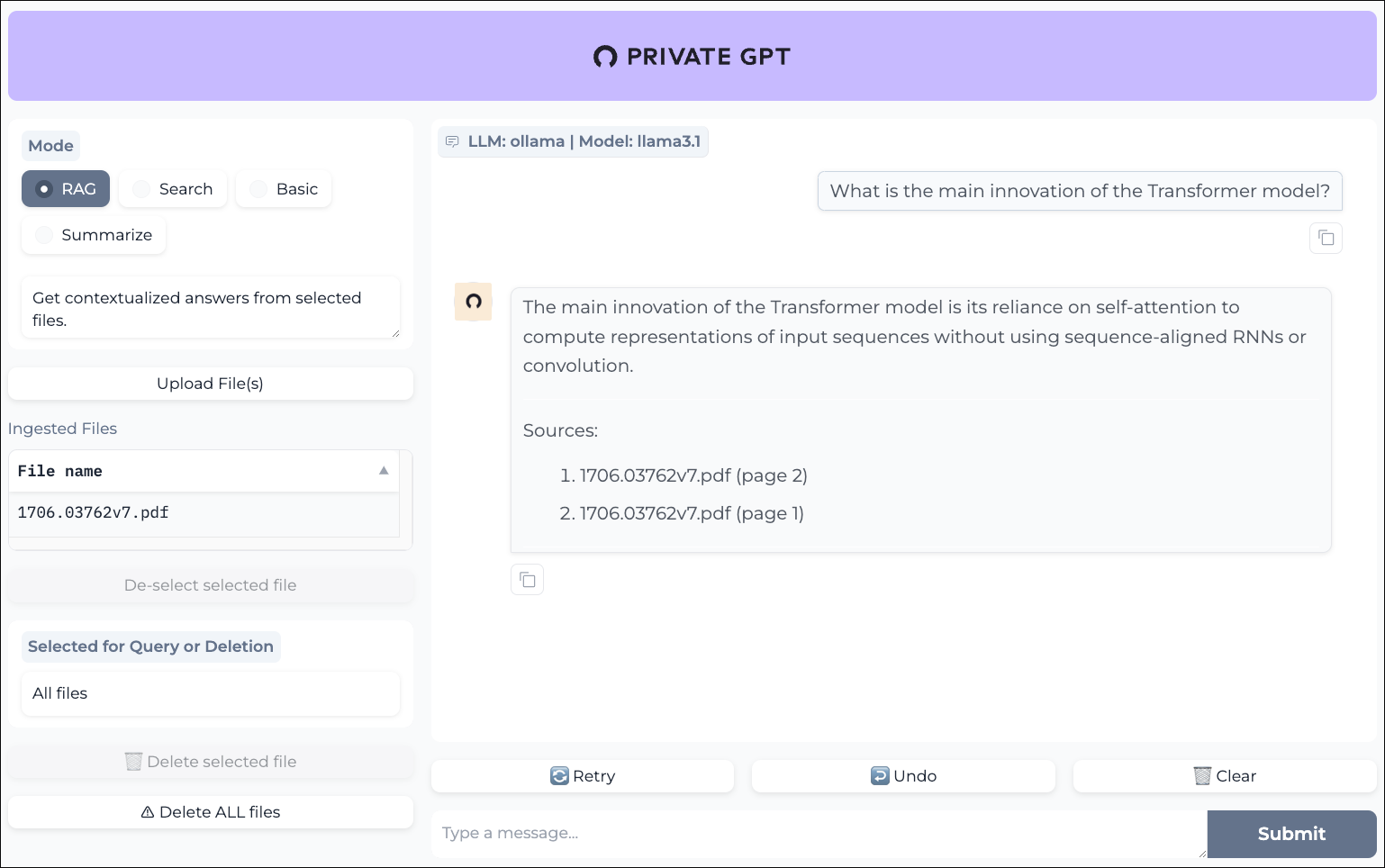
PrivateGPT can run inside a Docker container. It also integrates very easily with Ollama as the model backend. So, it works well with a setup that most are already familiar with and likely running inside their home lab or in some type of self-hosted way.
LibreChat
LibreChat is a tool that if you are looking for an alternative web UI that allows you to connect to various AI backends, including your Ollama environment or something like OpenAI. It makes this easy to do. It is forked from the official ChatGPT interface and is designed so that you can interact with open-source environments or commercial cloud environments. So there is no vendor lock-in here with the technologies you can use.
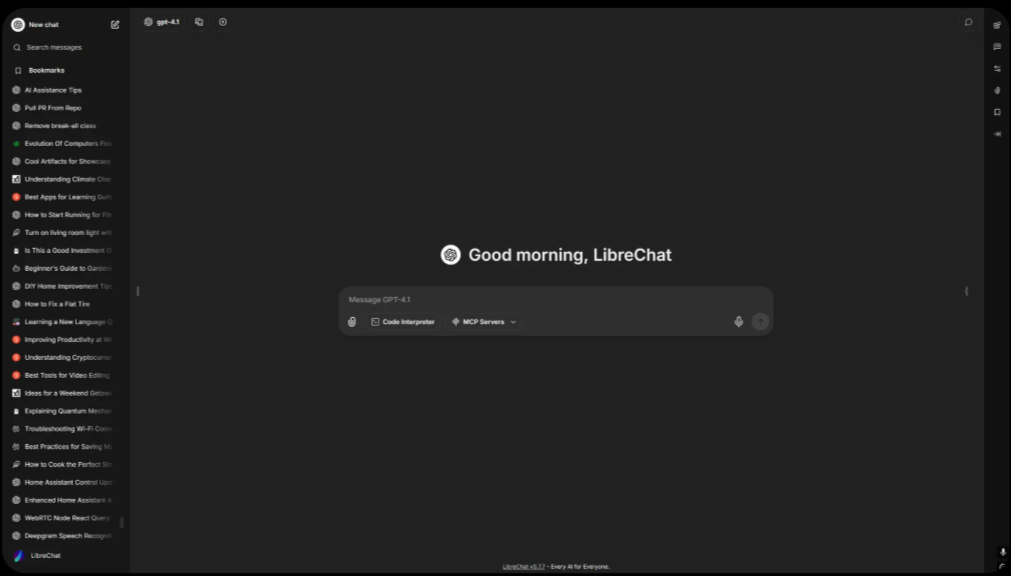
LibreChat supports a lot of different capabilities for your setup. It can support:
- multi-model setups
- plugins
- custom prompts
- chat memory
Another thing you can do with it that I really like is you can configure it to be a shared AI workspace for multiple users in your home lab. Let’s say you want to allow your kids or family to access AI. This gives you full control over where data is stored and what is accessed.
Putting it all together in your home lab
The best part about all these self-hosted AI tools is how easily they can work together in your home lab. With all of the tools, it might be a bit overwhelming to know how to put everything together and what you need to use where. Take a look at the following:
- Ollama is the engine that runs your local models so you can stand this up first and build around it
- OpenWebUI is the most popular open-source web interface for interacting with Ollama
- n8n is a tool that allows creating workflow automations that can trigger AI tasks or schedule summaries and posts
- Whisper is a tool that transcribes audio files and can be used to send them to something like n8n for summarization
- Stable Diffusion WebUI wraps the Stable Diffusion model with a really great web interface that allows you to create images based on those summaries for visual posts
- PrivateGPT or AnythingLLM can be used to index your local home lab documentation store so you can ask it questions about your environment
Everything here can run on a small Proxmox node or cluster of nodes, Docker Swarm, or even a single mini PC. The key advantage to all of these tools is control. You decide what data gets processed, where it’s stored, and which models you want to use.
Video
Wrapping up
There has never been a better time to self-host your AI solution in a home lab or on a home server. New and better tools keep popping up at lightning pace and it is hard to keep up sometimes with everything that is out there. Hopefully, my shortlist of great self-hosted AI tools that you can actually run in your home lab that are very good and allow you to have a very professional and “enterprisey” experience with AI models, will give you some ideas of what to try out next.
How about you? What AI tools are you self-hosting? Are you using something on this list or something else? Let me know in the comments.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author



Great write up. One item I like to point for the sake of security is to remember to use a vault or.gitignore cfg file for sensitive data so it doesn’t get uploaded to the AI repository.
John, great point! It is definitely important to make sure you handle any secrets according to best practices and use some type of vault to store them along with the .gitignore as you mention to make sure you don’t accidentally commit secrets.
Thanks for the informative article! I am going through this process currently with my Proxmox lab (old gaming system with Nvidia RTX 3070). I’d love to see an article/video on how you would set up WhisperX with n8n to automate the workflow you mention — that’s exactly what I need. Would you need multiple GPUs, given the need for multiple dockers (ollama, whisperx, n8n, etc), or can a single GPU be shared between dockers (yes, I’m a newbie at this!)
Vern,
I think we are all learning at this point with all the new tools and exciting tech we can now self-host so don’t feel bad. I am in no way an expert, just a tinkerer at heart gaining experience like the rest in the home lab and in the enterprise. You should be able to share GPU power between the Docker containers. When you run multiple containers, the NVIDIA driver handles scheduling and resources between the containers….so for example you could run all three of these on the same host (below). Definitely look for more videos on this stuff soon!
# Container 1 - Ollamadocker run -d --gpus all -p 11434:11434 --name ollama ollama/ollama
# Container 2 - Another AI service
docker run -d --gpus all -p 8000:8000 --name stable-diffusion some/stable-diffusion-image
# Container 3 - ComfyUI
docker run -d --gpus all -p 8188:8188 --name comfyui comfyui-image
As a follow up, have you considered reviewing/using Docker’s Model Runner for setting up a home lab? Thx for your efforts.
Vern,
Definitely looking at this as well! Cool stuff.
Brandon
You missed MSTY Studio which has the same front-end GUI capability as AnythingLLM and OpenWebUI and includes Ollama as its base engine.
Richard,
Awesome! I haven’t heart of MSTY studio, will definitely have to check it out. Sounds promising. Are there features you like about MSTY over the others?
Brandon
I used LM-studio for direct chat and to provide to opencode, anything-llm from other systems and comfyUI for image work
Very nice!