
I am loving being able to try out so many cool new AI models in 2025. There are so many great options to choose from now. Who would have thought we would have had so many different models from different vendors in play by now? It is easier than ever now to run AI locally and privately, using solutions like Ollama and OpenWebUI. I wanted to share a curated list of 10 models that I think are both relevant and great options for home lab environments, whether you are looking at general chatbot models, help with DevOps code, or something else Let’s look at what they are, what you can use them for, and what kind of hardware you might need in terms of VRAM to run them.
1. Gemma 3 and codegemma
When it comes to open source models you can use in your home lab for all kinds of use cases, Gemma 3 is hard to beat. It is Google’s lightweight multimodal family that is built from the Gemini technology that is used by Google online.
You can use it for many different use cases, including for text, coding, images, and many other things. It supports 128K context and comes in sizes ranging from 270M (tiny) and 1B up to 4B and 12B. Most likely for the hardware that many are running in their lab environments, the 4B variant is the sweet spot for capability vs resources required. You can use the 270M variant for quick chats or chat helpers if you want something that is fast and instruction tuned.
- Good for: lightweight assistants, RAG prototypes, multimodal tinkering, multilingual tasks
- Try in Ollama: gemma3:270m, gemma3:1b, gemma3:4b, gemma3:12b
- VRAM (Q4):
- 270M ≈ ~2 GB
- 1B ≈ ~3–4 GB
- 4B ≈ ~6–7 GB
- 12B ≈ ~12–14 GB
codegemma
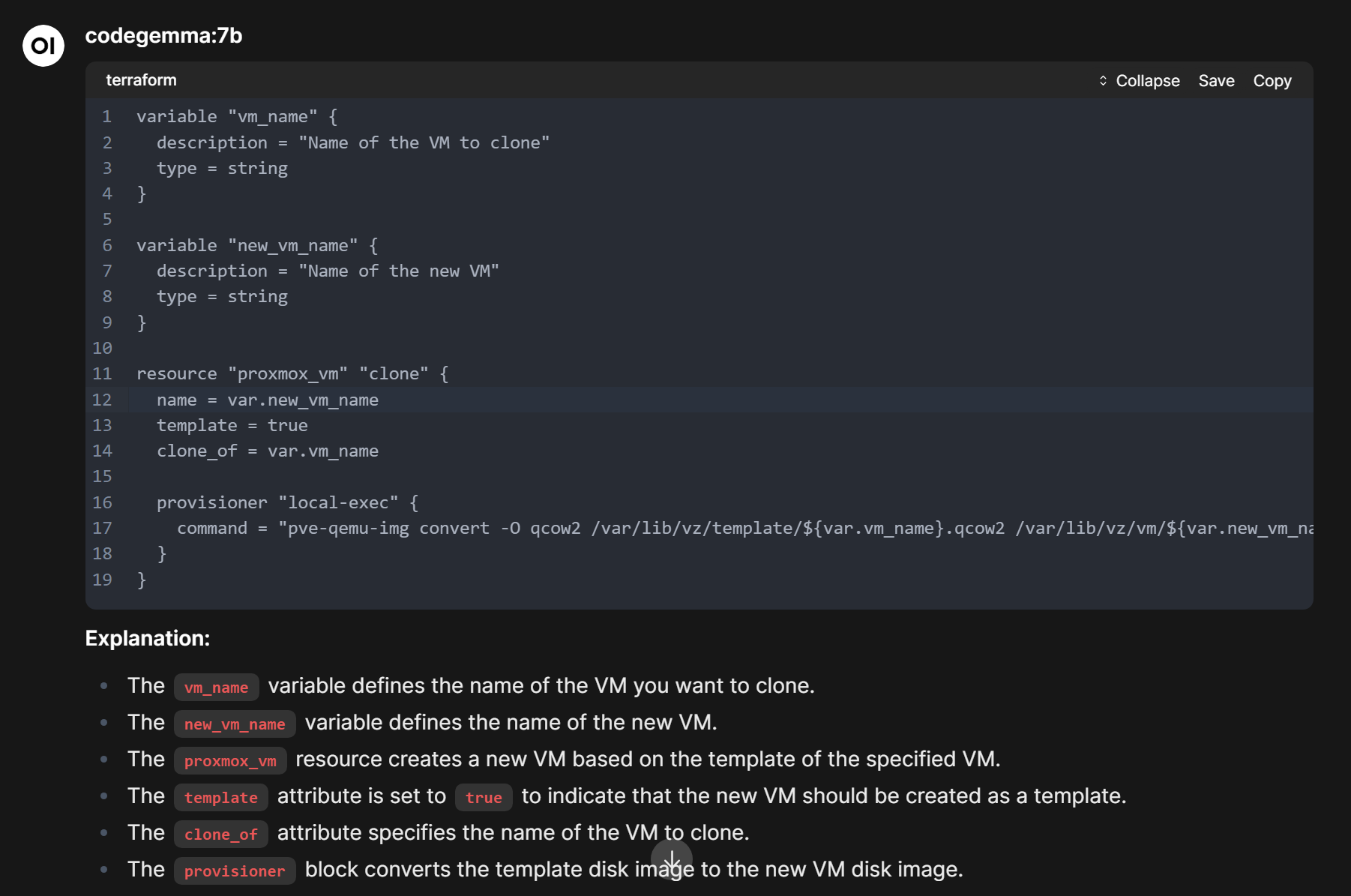
If you are looking for a great model for coding and DevOps’y tasks in the home lab, codegemma is also a great option. It is more focused on coding than gemma 3 which is a more generalist model. Take a look at this Terraform code I generated with codegemma:
How to pull Gemma 3
ollama pull gemma3:270m
ollama pull gemma3:1b
ollama pull gemma3:4b
ollama pull gemma3:12b
2. Gemma 3n (efficient “effective 2B/4B”)
There is another variant called the Gemma 3n model that targets even lighterweight devices like laptops and everyday devices. This model behaves like a 2B/4B model during inference even though there are more total parameters behind the scenes.
This one is great for very low-overhead assistants or if you want to use these to push small models on thin clients, or other lightweight devices.
- Good for: ultra-efficient local assistants, edge devices, always-on agents
- Try in Ollama: gemma3n:e2b (and other tags on the page)
- VRAM (Q4):
- effective 2B ≈ ~4–5 GB
- effective 4B ≈ ~6–7 GB
How to pull Gemma 3n
ollama pull gemma3n:e2b
ollama pull gemma3n:e4b3. Qwen 2.5:7b and qwen2.5-coder:7b
The Qwen 2.5 model is from Alibaba and is a general-purpose family of model much like Gemma. It has really good multilingual support and long context windows up to 128K. The model spans from tiny .5B up to 72B. So there is something for everyone here from very tiny GPU resources up to running multiple GPUs to handle the full 72B model. Qwen2.5 models are pretrained on Alibaba’s latest large-scale dataset, that includes up to 18 trillion tokens.
However, the sweet spot for Qwen 2.5 is the 7B and 14B models. The 7B model is a fast model and practical not requiring more than a medium-grade graphics adapter. 14B is capable of heavier reasoning and can still run on a single consumer-grade GPU.
qwen2.5-coder:7b
The coder version is great for code generation, code reasoning, and code fixing including general DevOps tasks. So, if you want to have a great model for helping with writing your DevOps infrastructure as code in the home lab, this is a very good one to use.
Qwen is good for:
- Good for: multilingual chat, reasoning, tool use prototypes, long-context summarization
- Try in Ollama: qwen2.5:4b, qwen2.5:14b (other sizes available)
- VRAM (Q4):
- 4B ≈ ~6–7 GB
- 14B ≈ ~12–14 GB
- 32B+ ≈ ~20 GB and up
How to pull Qwen 2.5
ollama pull qwen2.5:7b
ollama pull qwen2.5:14b
ollama pull qwen2.5-coder:7b
What about Qwen 3?
You may have seen there is a Qwen 3 that is available on Ollama as well and definitely try this one out too. The reason we are putting emphasis still on Qwen 2.5 is it already has well-quantized builds, includings Q4/Q5/Q8 that are widely available and it loads easily in Ollama and can be ran without lots of VRAM resources.
Qwen 3 is exciting but much heavier and newer, so it’s still ramping up in practical home lab use. Primarily it has:
- Stronger on reasoning, tool use, and multi-step tasks than Qwen 2.5
- VRAM needs are higher at the big scales (30B+ really wants 20–24 GB+)
- Still maturing in ecosystem support compared to 2.5 (fewer quant builds and fewer downstream projects using it yet)
4. Mistral 7B
The Mistral 7B model is a really great option for all around instruction following and it is also great for coding help. It is one of the most popular variants in the Ollama library and has variants like instruct. It is one that is a good model to choose if you want to have a balance between speed, quality, and not a lot of resources required from a VRAM perspective.
- Good for: general chat, summarization, light coding assistance, RAG demos
- Try in Ollama: mistral:instruct or mistral:latest
- VRAM (Q4): ~7–9 GB
How to pull Mistral 7B
ollama pull mistral:7b
5. Llama 3
Llama 3 is Metas open-source model that comes in the 8B and 70B sizes that can be found in the Ollama library. If you have a single GPU home lab device, the 8B option is the way to go. The 70B option will need a pretty extravagant multi-GPU configuration to run this satisfactorily without the need for waiting forever.
- Good for: capable general assistant, documentation Q&A, small coding tasks
- Try in Ollama:
llama3:8b(70B exists but is heavyweight) - VRAM (Q4):
- 8B ≈ ~8–10 GB
- 70B ≈ well beyond single 24 GB cards, will need purpose-built multi-Quadro cards likely
How to pull LLama 3
ollama pull llama3:8b6. Llama 3.2 (1B/3B small models)
Another really interesting model from Meta is Llama 3.2. This variant adds compact 1B and 3B models optimized for things like dialogue, and multi-lingual use cases. These models are extremely easy to run on minimal GPU hardware or even lower spec CPUs. You can use these models for embedded assistants for dev tools, homelab dashboards, or small automations.
- Good for: low-latency chat bots, CLI copilots, edge agents, multilingual helpers
- Try in Ollama: llama3.2:1b, llama3.2:3b
- VRAM (Q4):
- 1B ≈ ~2–3 GB
- 3B ≈ ~5–6 GB
How to pull LLama 3.2
ollama pull llama3.2:1b
ollama pull llama3.2:3b7. DeepSeek-R1 (reasoning-focused)
DeepSeek has turned the world of open-source AI models on its head. DeepSeek R1 is an open-source reasoning family model with models from very tiny up to very large models. You can choose between 7B/8B/14B as being the ones that are realistic for home labs. These are “thinking” models, and you will find these in the tags. If you want to experiment with “chain-of-thought” type prompts, scratchpad workflows or reasoning-heavy tasks, DeepSeek-R1 will excel at these.
- Good for: multi-step reasoning, planning, tool-use scaffolds, analysis prompts
- Try in Ollama: start with deepseek-r1:7b or deepseek-r1:14b (see Tags for options)
- VRAM (Q4):
- 8B ≈ ~8–10 GB
- 14B ≈ ~12–14 GB
How to pull DeepSeek-R1
ollama pull deepseek-r1:7b
ollama pull deepseek-r1:14b
8. OLMo 2 (AI2)
With OLMo 2, you have a very transparent and fully open training model that can be had at 7B and 13B. It is very similar in performance to other similar sized open/open-weight models. It is a really good model if you care about research-friendliness. Also, you get good repeatability and instruction-tuned behavior.
- Good for: reproducible experiments, RAG baselines, documentation bots
- Try in Ollama: olmo2:7b, olmo2:13b
- VRAM (Q4):
- 7B ≈ ~8–10 GB
- 13B ≈ ~12–14 GB
How to pull OLMo 2
ollama pull olmo2:7b
ollama pull olmo2:13b
9. Phi-3 / Phi-3.5 from Microsoft
This is one I played around with for quite some time in LM Studio. However, it is definitely one I keep in my list of models downloaded with Ollama. The Microsoft Phi models are small and extremely efficient with instruction tuning. The Phi-3 Mini 3.8B runs on very low-power GPUs and even with CPU-only inference. Phi-3.5 extends context to 128K and bumps up the quality of responses as well. These models are great for AI assistants and lightweight automations you might want to play around with in your home lab.
- Good for: quick chat helpers, batch data cleanup, small web agents, low-power use
- Try in Ollama: phi3:mini, phi3:medium, or phi3.5:mini
- VRAM (Q4):
- Mini 3.8B ≈ ~4–6 GB
- Medium 14B ≈ ~12–14 GB
How to pull Phi-3 and Phi-3.5
ollama pull phi3:mini
ollama pull phi3:medium
ollama pull phi3.5:mini10. LLaVA v1.6
LLaVA is a classic vision encoder plus an LLM for image-aware chats you might want to use. With v1.6 in Ollama, you can test tasks like describing screenshots you might take, or extract text from UIs. You can also use it to answer questions about images you might want to have it examine. With this one, you will need more VRAM than for just a text-only model. However, it is a great way to start exploring VLMs locally.
- Good for: screenshot QA, UI automation helpers, knowledge over diagrams/images
- Try in Ollama: llava:v1.6 (sizes 7B/13B/34B exist)
- VRAM (Q4):
- 7B VLM ≈ ~12–16 GB
- larger sizes scale up quickly
How to pull LLava 7b v1.6
ollama pull llava:7bBonus model: SmallThinker (3B)
SmallThinker is a compact reasoning model fine-tuned from Qwen2.5-3B-Instruct. It’s a neat option for CPU-heavy or very low-VRAM setups. You can use it if you want to experiment with chain-of-thought-style behavior. If you want a fast, always-running helper for small tasks, this one is a good one to look at.
- Good for: tiny reasoning agents, CPU-only experiments, devbox copilots
- Try in Ollama: smallthinker
- VRAM (Q4): ~4–5 GB
How to pull SmallThinker
ollama pull smallthinker
Picking the right size for your hardware
Just as a note, you can do A LOT when it comes to local AI models even with very modest hardware. Not long ago I wrote up a post about using a super old NVIDIA GeForce GTX 1060 card with 6 GB of RAM and I was pleasantly surprised at what I could do with it. Take a look at my post here:

As a quick sanity check you can probably run a 1-3B class model on almost anything. Models from 4–8B will work great on 8–10 GB VRAM. Models that are 12–14B like 12–16 GB VRAM. Then 30B+ really wants 20–24 GB or more. If you’re CPU-only, everything will run, but you’ll feel quite pained above ~7B unless you are ok with very short contexts.
Compare them in a table
| Model family | Example Ollama tags | Strengths | Home-lab use cases | Approx VRAM (Q4) |
|---|---|---|---|---|
| Gemma 3 | gemma3:270m gemma3:1b gemma3:4b gemma3:12b | Multimodal, 128K context, multilingual | General assistant, RAG, vision+text | 270M ~2 GB, 1B ~3–4 GB, 4B ~6–7 GB, 12B ~12–14 GB |
| Gemma 3n | gemma3n:e2b (and others) | Designed for edge devices; selective activation | Ultra-efficient helpers, laptops/tablets | e2b ~4–5 GB, e4b ~6–7 GB |
| Qwen 2.5 | qwen2.5:4b qwen2.5:14b (many sizes) | Strong multilingual + long context | Chat, summarization, tool use | 4B ~6–7 GB, 14B ~12–14 GB, 32B+ ~20 GB+ |
| Mistral 7B | mistral:instruct | Fast, well-tuned 7B | General chat, coding helper | ~7–9 GB |
| Llama 3 | llama3:8b | Capable 8B generalist; huge ecosystem | Everyday assistant, doc Q&A | 8B ~8–10 GB (70B is far heavier) |
| Llama 3.2 | llama3.2:1b llama3.2:3b | Small, optimized for dialogue | CLI copilot, dashboards, edge agents | 1B ~2–3 GB, 3B ~5–6 GB |
| DeepSeek-R1 | deepseek-r1:7b deepseek-r1:14b | Reasoning-focused variants | Planning, tool-use scaffolds | 7–8B ~8–10 GB, 14B ~12–14 GB |
| OLMo 2 | olmo2:7b olmo2:13b | Open training recipe, strong baselines | Reproducible RAG, research | 7B ~8–10 GB, 13B ~12–14 GB |
| Phi-3 / 3.5 | phi3:mini phi3:medium phi3.5:mini | Efficient small models, long context on 3.5 | Lightweight assistants, batch jobs | Mini 3.8B ~4–6 GB, Medium 14B ~12–14 GB |
| LLaVA v1.6 | llava:v1.6 (7B/13B/34B) | Vision + language | Screenshot QA, image-aware chat | 7B VLM ~12–16 GB; larger |
Wrapping up which model
There are many different models that are well suited for various projects. If you’re on 8–10 GB VRAM, you can start with something like mistral:7b, llama3:8b, or qwen2.5:4b. If you’ve got 12–16 GB, this will allow you to run something like gemma3:12b, qwen2.5:14b, olmo2:13b, and mid-sized DeepSeek-R1. For laptop-class hardware, there are very small models like llama3.2:1b/3b, phi3:mini, smallthinker, and gemma3:270m that are perfect for that. And if you want to play with vision, llava is the easiest way to get hands-on multimodal in a home lab. Let me know in the comments which models you are using and what use cases you are using them for.
Google is updating how articles are shown. Don’t miss our leading home lab and tech content, written by humans, by setting Virtualization Howto as a preferred source.
About The Author



